Overview of Frauds in the Financial Industry:
Fraud is a significant challenge in the finance industry and can have severe consequences for individuals, and organizations. As financial institutions today adopt cloud technologies and other online payment solutions across the global, we are witnessing a steep rise in the number of frauds of various kinds. A recent report indicates that financial fraud is a significant issue for many financial services firms and can result in billions of dollars in losses. Direct losses by merchants and banks exceeded $32 billion globally last year according to Nilson Report released last year.
Online fraud takes many forms, including fake reviews, account takeovers, spam, synthetic identity frauds and bot attacks. While financial institutions use various methods to combat online fraud, simple rule-based techniques and feature-based algorithm techniques such as logistic regression, Bayesian belief networks, and CART may not always be effective in detecting the full range of fraudulent activities.
Fraudsters use sophisticated methods to avoid detection, such as setting up coordinated accounts, which can make it challenging to detect fraudulent behavior patterns at scale. Furthermore, detecting fraudulent behaviour patterns is complex due to the massive amount of data to sift through, and there is a scarcity of actual fraudulent cases required to train classification algorithms.
- Fraudulent transactions cost firm a lot of money. They also increase the brand and reputation risks as these incidents question an organization’s integrity and vigilance
- Rule based systems in place needs to be revised regularly to address the latest patterns of scams, account takeovers and illegal transactions.
How Machine Learning addresses some of these challenges:
Machine learning (ML) is a powerful tool that can be used for financial fraud detection. ML algorithms can analyze vast amounts of transaction data and identify patterns of behavior that are indicative of fraud.
One way in which ML is helping with financial fraud detection is through the use of anomaly detection algorithms. These algorithms can identify transactions that are unusual or suspicious based on various features, such as the amount, frequency, and location of the transactions. Anomaly detection algorithms can be trained using historical data to learn what typical transaction patterns look like, enabling them to identify anomalous behavior and flag potential cases of fraud.
ML algorithms can also be used to improve fraud prevention by identifying potential risks before fraudulent activity occurs. For example, ML algorithms can be used to identify high-risk accounts based on various factors, such as the age and location of the account holder, the type of transactions conducted, and the history of the account. Financial institutions can then take steps to monitor these high-risk accounts more closely and act if any suspicious activity is detected.

Figure1: Algorithms can efficiently identify fraudulent transactions based on the user data (Source: Author)
Challenges in current ML approaches
These algorithms need to be trained using labelled data, which can be difficult to obtain due to the small number of fraudulent transactions that actually happen compared to legitimate ones. However, techniques such as oversampling and undersampling can be used to address this issue today by balancing the number of fraudulent and legitimate transactions in the training data.
For example, in case of credit card frauds, the fraudsters come together and creates multiple bank accounts (often spanning different time and geographies) to make them look like genuine accounts. Traditional ML approaches fail to uncover the network of fraudsters hiding among the genuine accounts. Often the data containing flagged transactions are not exhaustive(since the suspicious account makes a few genuine transactions before they start) and hence these models that are trained in those data are usually unsuccessful in discovering coordinated attacks as in case of credit card frauds which uses multiple accounts.
In the following section, let’s explore how graph database and graph neural networks help address some key issues pointed out in the above sections in the context of credit card frauds—or any case involving more than one perpetrator.
Graph Neural Networks (GNN)
In the classical ML approach where we train predictive algorithms like decision trees, random forest or XGBoost, we typically store the transactions data in tabular format with columns as features. However, in the financial realm, transactions can be efficiently stored as graph databases where each node represents accounts and each edge represents transactions. The node will contain features associated with that account (ie location, data, etc). This representation of the existing transactional data helps the stakeholder understand different properties linked to a fraudulent account.
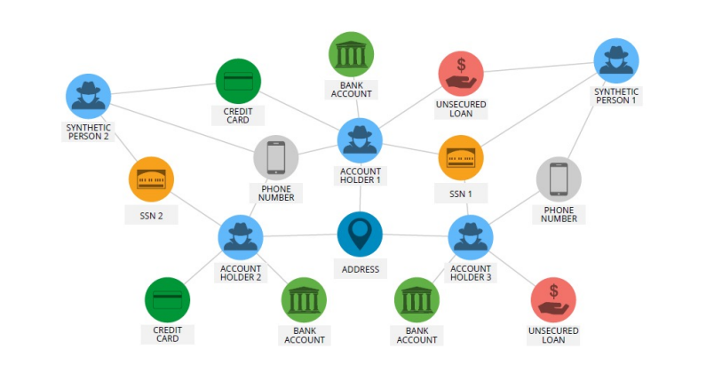
Figure: Graphs makes it easy to understand different connection between the data (Source: neo4j.com)
This helps us with analysis and predictions at different levels:
• Node Classification: the task here is to determine the labelling of samples (represented as nodes) by looking at the labels of their neighbors. Account level predictions are not very popular in the traditional ML approach since in most of the cases, we predict if the transaction is fraud or not.
• Link Predictions: Link represents transactions or any activity between nodes. A simple use case could be detecting suspicious transactions from genuine accounts could indicate theft or illegal account take overs.
• Community classifications: Within the entire network of transactions and accounts, it is now possible to uncover clusters with strong similarities. These would help the model to predict and classify accounts vulnerable to attacks or find group of illegal accounts.
• Anomaly Detection: In a collection of nodes, we find outliers in the graph in an unsupervised manner (data with no labels).
•Graph classification: the task here is to classify the whole graph into different categories. The applications of graph classification are numerous and range from determining whether a protein is an enzyme or not in bioinformatics, to categorizing documents in NLP, or social network analysis.
Application of GNN in Industry Use Cases
GNN-based models, such as RGCN, can benefit from topological information by combining network structure and node and edge attributes to build a meaningful representation that separates fraudulent from legitimate transactions. By heterogeneous graph embedding, RGCN can efficiently learn to represent many kinds of nodes and edges (relations).
• Loan Default Risk: For commercial banks and financial regularity institutions, monitoring and assessing the default risk is at the heart of risk controlling process. As one of the credit risks, default risk is the probability that the borrower fails to pay the interest and principal on time. With a binary outcome, loan default prediction could be seen as a classification problem and is commonly addressed utilizing user-related features with classifiers including neural network and gradient boosted trees. Since the probability that a borrower defaults may be influenced by other related individuals, there is plenty of literature forming a graph to reflect the interactions between borrowers. With the rapid growth of GNN methods, GNN methods are widely applied on the graph structure for loan default predicting problems.
• Stock movement Prediction: Though there are still debates on whether stocks are predictable, stock prediction receives great attention and there are rich literature on predicting stock movements utilizing machine learning methods. However, the task of stock prediction is challenging due to the volatile and non-linear nature of the stock market. The limitation of these non-graph approaches is that they often have a hidden assumption that the stocks are independent. To take the dependence into account, there is an increasing trend to represent the stock relations in a graph where each stock is represented as a node and an edge would exist if there are relations between two stocks. Predicting multiple stocks’ movements could then be formed as a node classification task and graph neural network models could be utilized to make the prediction.
• Fraud Detection: Observing that fraudsters tend to have abnormal connectivity with other users, there is a trend to present users’ relations in a graph and thus, the fraud detection task could be formulated as a node classification task. Aiming to detect the malicious accounts, who may attack the online services to seek excessive profits, studies show that fraudsters have two patterns: device aggregation and activity aggregation. Due to economic constraints, attackers tend to use limited number of devices and perform activities in a limited time, which may be reflected in the local graph structure.
• Event Prediction: Financial events, including revenue growth, acquisition and bankruptcy, could provide valuable information on market trends and could be used to predict future stock movement. Therefore, it draws great attention on how to predict next financial event based on past events and currently GGNN model is often used to accomplish the task.
(ref: A Review on Graph Neural Network Methods in Financial Applications | DeepAI)
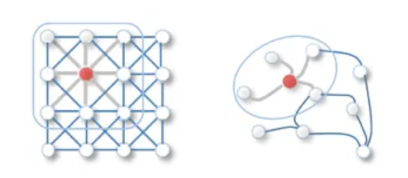
Figure: Image convolution and Graph convolution (Source: towardsdatascience)
The intuition of GNN is that nodes are naturally defined by their neighbors and connections. To understand this, we can simply imagine that if we remove the neighbors and connections around a node, then the node will lose all its information. Therefore, the neighbours of a node and connections to neighbours define the concept of the node.
An important aspect of the training while implementing graph neural network is a process called Graph Convolution. In many ways the idea behind this is similar to that of image convolution which is widely used in image processing. The idea of convolution on an image is to sum the neighboring pixels around a center pixel, specified by a filter with parameterized size and learnable weight. Spatial Convolutional Network adopts the same idea by aggregate the features of neighboring nodes into the center node.
Advantages of using GNN over classic ML algorithms
The reason why this approach is more effective is because each node is classified not just by looking into the node features, but also the neighboring nodes. The task of all GNN is to determine the “node embedding” of each node, by looking at the information on its neighboring nodes.
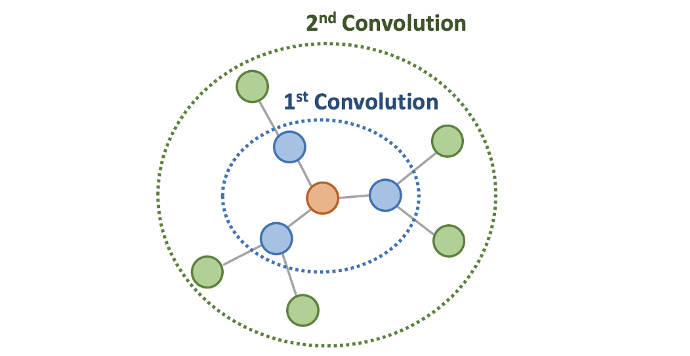
Figure: Each node prediction is arrived at by considering the node’s feature and its neighbors (Source: towardddatascience)
This allows the model to recognise the node’s connection with other nodes that are further away. Hence it is now possible to discover hidden pattern that would have not been captured by other traditional algorithms.
When multiple layers of graph convolution are performed, this results in a node’s state containing some information from nodes multiple layers away, effectively allowing the GNN to have a “receptive field” of nodes or edges multiple jumps away from the node or edge in question. This is different from the anomaly detection using random forest. In random forest algorithm, the model finds columns(or features) that can split the data into two parts resulting in a more pure subsets of each classes (fraud or not_fraud) and where the depth of traversal is indicative of anomaly. The model does not look into all the features of a user at once. However in case of graph neural network, with each convolutional layers, the model looks not only at every features of a user, but multiple users at a time.
In the context of the fraud detection problem, this large receptive field of GNNs can account for more complex or longer chains of transactions that fraudsters can use for obfuscation. Additionally, changing patterns can be accounted for by iterative retraining of the model.
Explainability is Necessary
Predicting whether a transaction is fraudulent or not is not sufficient for transparency expectations in the financial services industry. It is also necessary to understand why certain transactions are flagged as fraud. This explainability is important for understanding how fraud happens, how to implement policies to reduce fraud, and to make sure the process isn’t biased. Therefore, fraud detection models are required to be interpretable and explainable which limits the selection of models that analysts can use.
One of the reasons why the industry has been reluctant to use neural networks is because they have to be treated like a black box. It is not clear why such model classifies something or which features have been crucial in making a prediction. Classical ML approaches had an edge over neural networks in this case. For example, decision tree algorithms use a metric called Information Gain to split the features efficiently into separate classes. This allows us to see which features have been more useful for making predictions.
Researchers are now putting a lot of effort in making GNN more explainable. GNNExplainer, for example, is proposed to provide an interpretable explanation on trained GNN models such as GCN and GAT. Model explainability in financial tasks is of great importance, since understanding the model could benefit decision-making and reduce economic losses.
Implementing GNN on cloud: Scalability
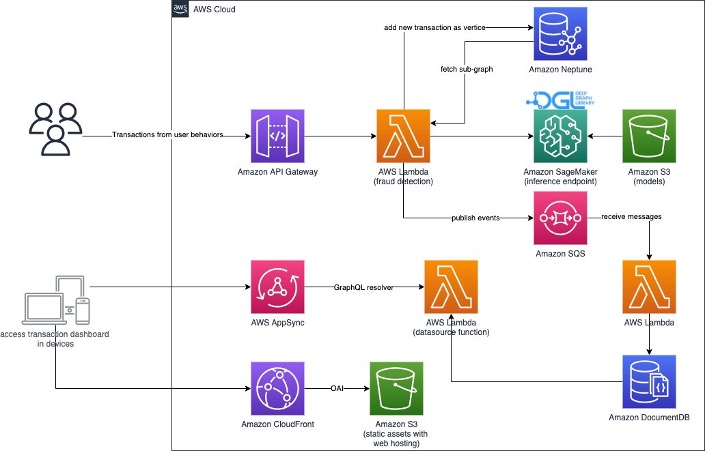
Figure: Implementing real time prediction on AWS (Link to Github repo)
It's critical to predict frauds in real time. Nevertheless, creating such a solution is challenging. There are not many online resources on converting GNN models from batch serving to real-time serving because GNNs are still relatively novel to the industry. Building a streaming data pipeline that can send incoming events to a GNN real-time serving API is also difficult since the dimension is very high and nodes are densely grouped hence its computationally heavy.
Cloud service providers like AWS have launched services to help developers apply GNN to real-time fraud detection. Amazon Neptune is a fully managed database service built for the cloud that makes it easier to build and run graph applications. Neptune provides built-in security, continuous backups, serverless compute, and integrations with other AWS services like Sagemaker, Glue, S3 and many others.
Amazon Neptune ML is a new capability of Neptune that uses Graph Neural Networks (GNNs), a machine learning technique purpose-built for graphs, to make easy, fast, and more accurate predictions using graph data. With Neptune ML, you can improve the accuracy of most predictions for graphs by over 50% (study by Stanford) when compared to making predictions using non-graph methods.
Conclusion
This article makes a case for using graph neural networks for detecting fraud as compared to other available ML approaches which were originally designed for tabular data. GNN models can develop meaningful representations to separate fraudulent users and events from legitimate ones by combining graph structure with qualities of nodes or edges, such as users or transactions. This capability is essential for identifying frauds in which fraudsters cooperate to mask their odd features while yet leaving some indications of relations.
In conclusion, utilizing ML or Neural Networks for fraud detection is a viable approach for businesses to protect themselves from the increasing prevalence and cost of frauds and scams. It is also important to create a data culture within businesses to leverage the existing data to gain deep, actionable and rich insights on potential areas of fraud and to perform advance analytics on them. Combining the power of AI and cloud technologies like AWS, businesses can detect and prevent frauds in real-time, gain competitive advantages, mitigate fraud risks and protect their financial assets.
— Author: Blesson Davis
 Go to Swayam
Go to Swayam