 Go to Swayam
Go to Swayam- Home
- About
- Consulting
- Services
- Minfy Labs
- Industries
- Resonances
- Careers
- Contact
As organizations generate massive amounts of data from various sources, the need for a scalable and cost-effective data storage and processing solution becomes critical. AWS (Amazon Web Services) offers a powerful platform for building a scalable data lake, enabling businesses to store, process, and analyze vast volumes of data efficiently. In this blog, we will dive deep into the process of constructing a robust and scalable data lake on AWS using various services like Amazon S3, AWS Glue, AWS Lambda, and Amazon Athena.
Defining a Data Lake
Before dive in, let's define what a data lake is. A data lake is a central repository that allows organizations to store and process vast amounts of structured and unstructured data at any scale. Unlike traditional databases or data warehouses, a data lake is flexible, capable of accommodating diverse data types, and can scale easily as data volumes increase.
In a data lake, there are entities known as data producers and data consumers. Data producers are responsible for gathering, processing, and storing data within their specific domain, which collectively makes up the content of the data lake. They have the option to share specific data assets with the data consumers of the data lake. Data consumers are users, applications, or systems that retrieve and analyse data from the data lake. They can be data analysts, data scientists, machine learning models, or other downstream processes. Tools like Amazon Athena and Amazon Redshift are used for querying and analysing data within the data lake.
Planning the Data Lake
A scalable data lake architecture establishes a robust framework for organizations to unlock the full potential of its data lake and seamlessly accommodate expanding data volumes. By ensuring uninterrupted data insights, regardless of scale, this architecture enhances your organization's competitiveness in the ever-evolving data landscape.
Efficiently managing data ingestion into data lakes is crucial for businesses as it can be time-consuming and resource-intensive. To optimize cost and extract maximum value from the data, many organizations opt for a one-time data ingestion approach, followed by multiple uses of the same data. To achieve scalability and cater to the increasing data production, sharing, and consumption, a well-thought-out data lake architecture becomes essential. This design ensures that as the data lake expands, it continues to deliver significant value to various business stakeholders.
Having a scalable data lake architecture establishes a strong framework for extracting value from the data lake and accommodating the influx of additional data. This uninterrupted scalability empowers the organization to continuously derive insights from the data without facing constraints, ensuring sustained competitiveness in the market.
Data Variety and Complexity:
As a data lake scales, the variety of data formats and structures also increases. This makes it challenging to maintain a unified data schema and to ensure compatibility across various data sources.
Data Ingestion Performance:
Scaling the data lake can lead to bottlenecks in data ingestion pipelines. High data volumes require efficient and parallelized data ingestion mechanisms.
Data Security and Access Control:
As the data lake grows, managing data access becomes crucial. Ensuring secure access to sensitive data while facilitating easy access for authorized users is a complex task.
Data Quality and Governance:
Maintaining data quality and enforcing governance policies become more difficult at scale. It's essential to have mechanisms to validate, cleanse, and transform data as it enters the lake.
Data Partitioning and Organization:
Proper data partitioning and organization are essential for efficient querying and processing. Without a thoughtful approach, query performance can degrade significantly.
Let's walk through the steps of building a scalable data lake on AWS, addressing the challenges mentioned above.
Amazon S3 Bucket Creation
• Log in to the AWS Management Console and navigate to the S3 service
• Create a new S3 bucket to store the raw data. Choose a unique bucket name, select the desired region, and configure the required settings (e.g., versioning, logging)
• Set up a folder structure within the bucket to organize data by source, date, or any relevant category. This structure helps in managing large volumes of data efficiently
AWS Glue for Data Catalog and ETL
AWS Glue allows us to discover, catalog, and transform data. It creates a metadata repository (Data Catalog) that helps in tracking data and schema changes. Additionally, Glue provides ETL capabilities to convert raw data into structured formats for querying.
• Go to the AWS Glue service in the AWS Management Console
• Create a new Glue Data Catalog database and relevant tables based on your data structure
• Define Glue ETL jobs using Python or Scala code to transform the data into a desired format.
• Here's an example of a Glue ETL job using Python:

Amazon Athena for Querying Data
Amazon Athena allows you to perform ad-hoc SQL queries on the data stored in S3 without the need for any data transformation upfront. It enables you to gain insights directly from the raw data.
• Go to the Amazon Athena service in the AWS Management Console
• Create a new database and corresponding tables in Athena using the Glue Data Catalog
• Write SQL queries to analyse and extract insights from the data. For example;

Data Ingestion into the Data Lake
Batch Data Ingestion
To ingest data into the Data Lake, you can use various methods, such as AWS DataSync, AWS Transfer Family, or AWS Glue DataBrew for data preparation. For batch data ingestion, AWS Glue ETL jobs can be scheduled to run periodically or triggered by specific events. Example of using AWS Glue DataBrew for batch data ingestion:

Real-time Data Ingestion
For real-time data ingestion, you can use services like Amazon Kinesis or AWS Lambda. Here's an example of using AWS Lambda to ingest real-time data into the Data Lake:

Defining Schema and Data Types
It is essential to define the schema and data types for the data stored in the Data Lake. This helps in ensuring consistent data and enables better query performance. You can use tools like AWS Glue Crawler to automatically infer the schema from the data, or you can provide a schema manually.
Data Cleaning and Standardization
Before performing analytics, it's crucial to clean and standardize the data to remove any inconsistencies and ensure data quality. You can achieve this through AWS Glue ETL jobs, using Spark transformations or Python functions.
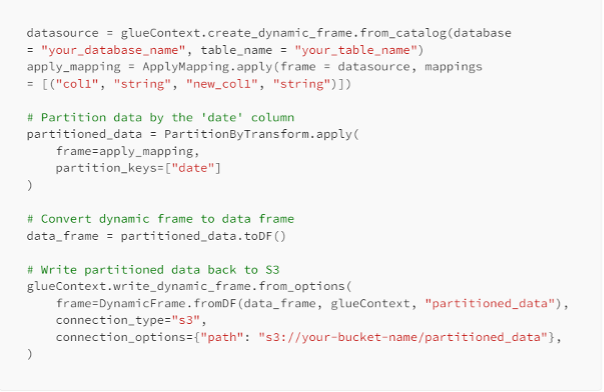
Partitioning Data for Performance
Partitioning data in the Data Lake helps improve query performance, especially for large datasets. It allows for faster data retrieval and reduces the data scan size. You can partition data based on relevant columns like date, region, or category.
Example of partitioning data in AWS Glue ETL job:
IAM Policies
AWS Identity and Access Management (IAM) policies help manage permissions and access to AWS resources. Ensure that you have defined appropriate IAM policies to control access to S3 buckets, Glue Data Catalog, and other services.
Example of an IAM policy for a user with access to specific S3 buckets:

S3 Bucket Policies
S3 bucket policies allow fine-grained control over access to the bucket and its objects. You can define policies to grant specific permissions to specific users or groups.
Example of an S3 bucket policy allowing read access to specific IAM users:

Amazon Redshift for Data Warehousing
For advanced analytics and data warehousing, you can integrate Amazon Redshift with your Data Lake. Amazon Redshift provides a high-performance data warehouse that allows you to run complex SQL queries and perform OLAP (Online Analytical Processing) tasks.

Amazon QuickSight for Data Visualization
Amazon QuickSight offers an easy-to-use business intelligence tool that enables you to create interactive dashboards and visualizations from data in your Data Lake.
Example of creating a QuickSight dashboard:
• Connect QuickSight to your Data Lake by creating a dataset
• Choose the relevant data tables from the Data Catalog.
Use the drag-and-drop interface to create visualizations and assemble them into a dashboard.
Data Governance and Compliance
Ensure that your Data Lake adheres to data governance and compliance standards, especially if you deal with sensitive or regulated data. Implement encryption mechanisms for data at rest and in transit, and apply access control to restrict data access to authorized users only.
Data Lake Monitoring and Scaling
Implement monitoring and logging mechanisms to track the performance, health, and usage of your Data Lake components. Use AWS CloudWatch for monitoring and set up alarms for critical metrics.
Additionally, design your Data Lake to scale effectively with growing data volumes. AWS services like S3 and Glue are designed to handle large-scale data, but it's essential to optimize your data storage and processing to ensure smooth performance.
Conclusion
Building a scalable data lake using AWS S3, Glue, and Lake Formation empowers organizations to handle vast amounts of data and extract valuable insights. With the steps and code examples provided in this blog post, you have the foundation to create a powerful data lake architecture that supports data-driven decision-making and analytics.
By following these best practices and utilizing AWS services, you can overcome the challenges of scaling a data lake and build a robust, scalable, and efficient data infrastructure that empowers your organization to extract valuable insights from your data.
Remember that data lake implementations can vary based on specific use cases and requirements. Be sure to continuously monitor and optimize your data lake architecture to make the most of AWS's powerful services.
— Yasir UI Hadi
References
https://docs.aws.amazon.com/prescriptive-guidance/latest/data-lake-for-growth-scale/welcome.html
https://aws.amazon.com/solutions/implementations/data-lake-solution/
This website stores cookie on your computer. These cookies are used to collect information about how you interact with our website and allow us to remember you. We use this information in order to improve and customize your browsing experience and for analytics and metrics about our visitors both on this website and other media. To find out more about the cookies we use, see our Privacy Policy. If you decline, your information won’t be tracked when you visit this website. A single cookie will be used in your browser to remember your preference not to be tracked.