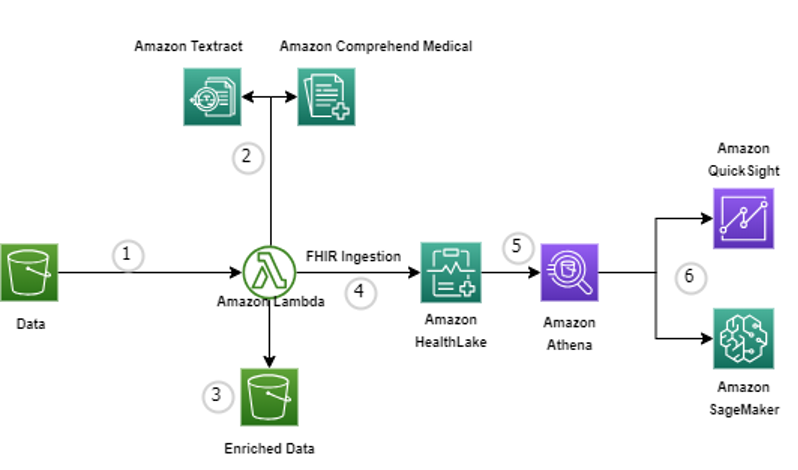
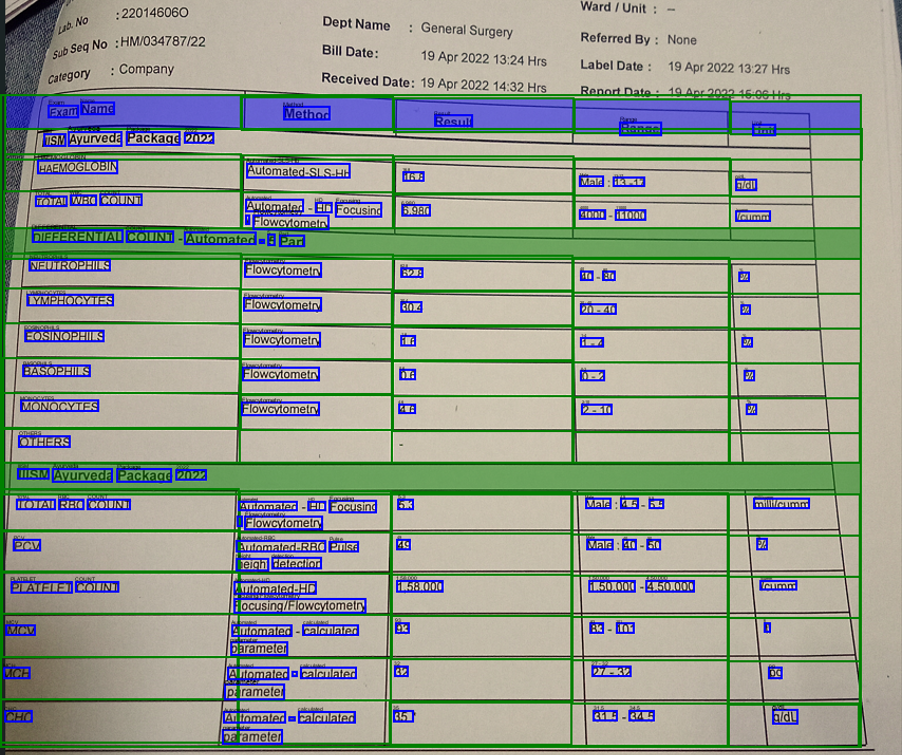
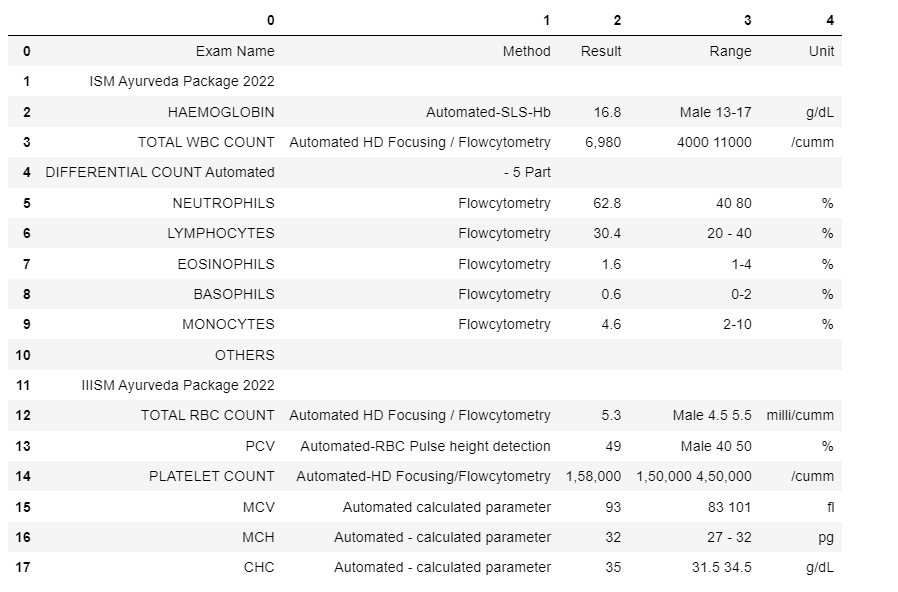
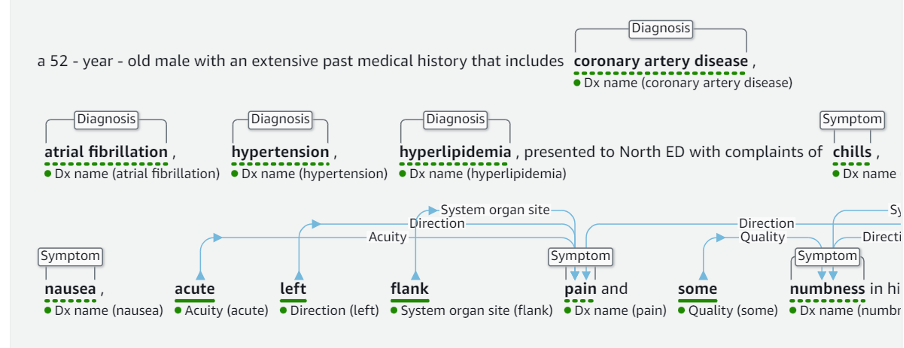
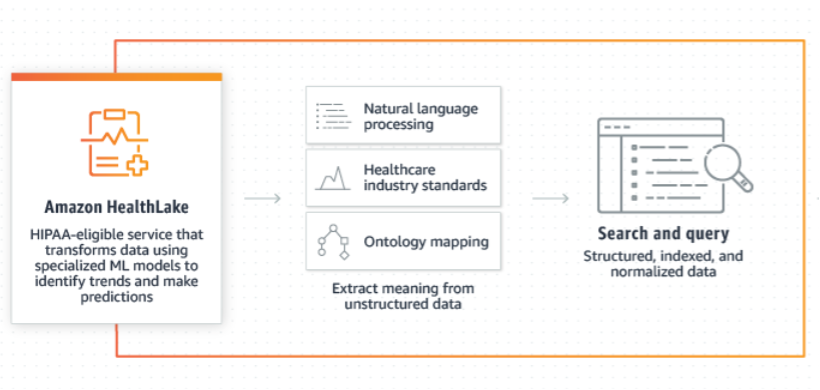
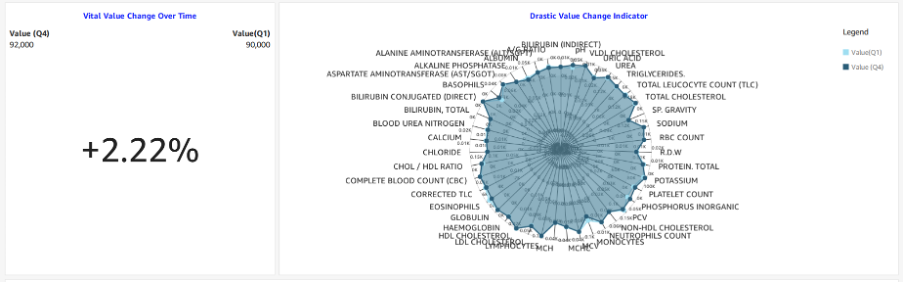
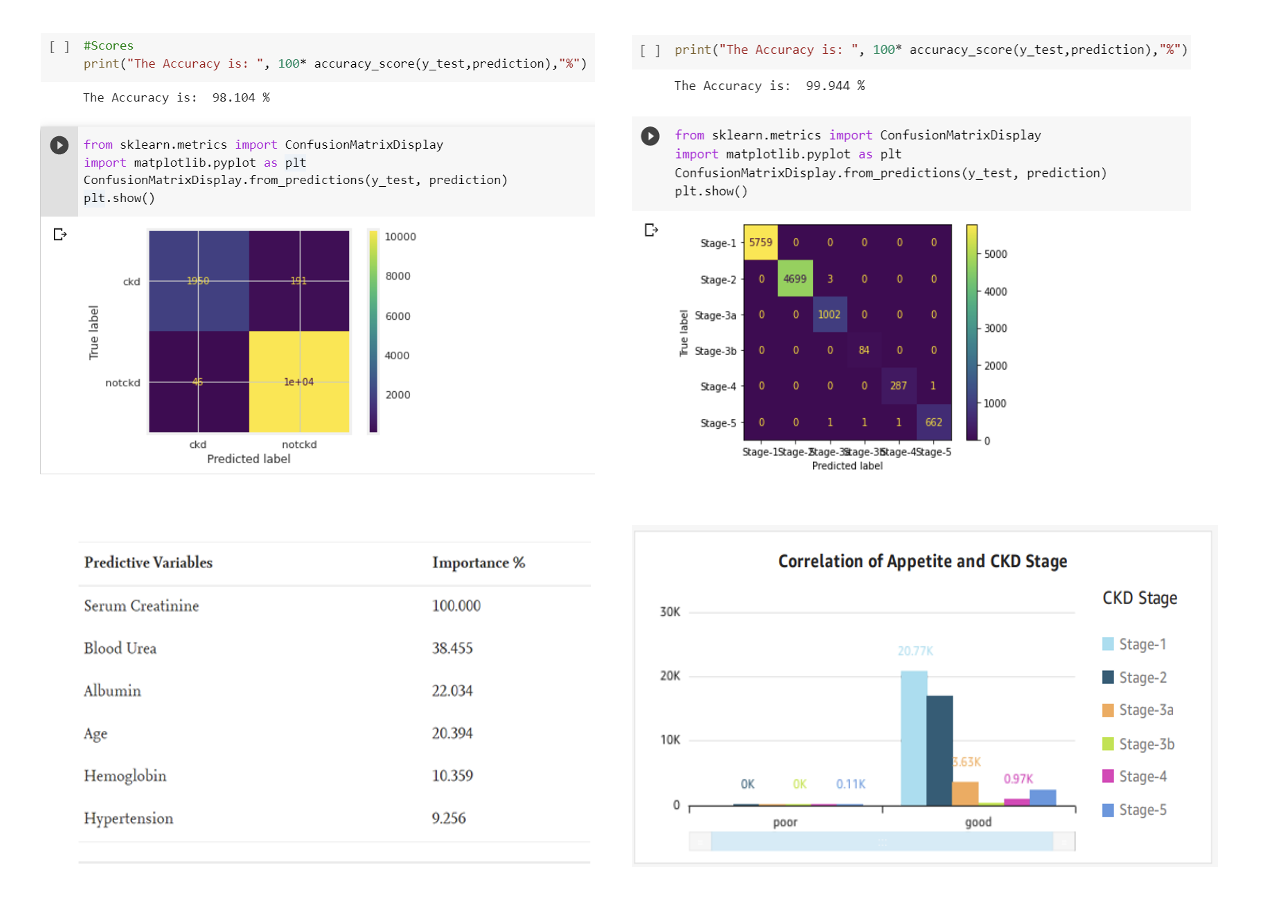
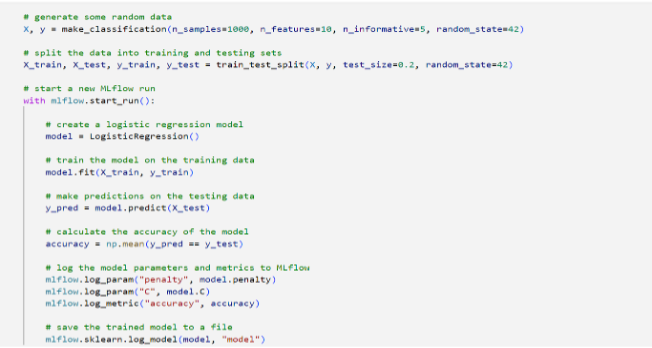
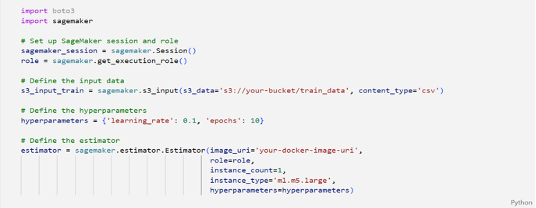
AWS re:Invent 2023 starts next week from Monday Nov 27th and it is expected to be a week of exciting announcements on cloud, data and AI. Watch out for keynotes from Adam Selipsky, Swami Sivasubramanin, Werner Vogels, Ruba Borno and others.
If you are attending re:Invent, say hello to the Minfy Team and follow our posts on LinkedIn. Minfy is a Cloud, Data, AI company that can accelerate your digital transformation at a lower cost.
Join team Minfy leaders: @Sachin Sharma @jaideep Sen @Nikhil Polepally @Karan Mutha @Raj Chilakapati @Vivek Jain @Vijay Jain
Customers are invited to join Minfy for an exciting evening at the Spheres on Tuesday Nov 28 or for dinner on Wednesday Nov 29th (by invitation only - limited seats available. Please reach out to @jaideep Sen).
We have exciting updates on solutions and offers that can accelerate your cloud, data and AI journey.
Our experts will be happy to provide you with valuable insights, answer your questions, and demonstrate how Minfy can help you transform your technology landscape. You can check out our success stories and solutions factory as well.
Now, let's get back to help you navigate the AWS re:Invent 2023.
A Glimpse into AWS re:Invent
For those who are new to AWS re:Invent or need a quick refresher, this conference is AWS's premier event, offering a comprehensive and immersive experience for cloud professionals. It's the perfect opportunity to get hands-on access and learn from AWS experts, whether you're a certified AWS pro or just getting started. You'll gain new skills, explore innovative use cases, and stay up-to-date with the latest developments in the AWS ecosystem.
Who Attends AWS re:Invent?
AWS re:Invent attracts a diverse and dynamic crowd, bringing together individuals and organizations from all corners of the tech world. In addition to the strong Amazon community, you can expect to meet enthusiasts, industry leaders, and representatives from renowned tech giants like Red Hat, Cisco, Accenture, TCS, Infosys, and, of course, Minfy!
This global cloud community has been converging at re:Invent for over a decade to network, find inspiration, and foster innovation. Attendees can look forward to a wide range of activities, including:
A. Bootcamps: These are designed to expand your understanding of AWS services and prepare you for certification exams.
B. Breakout Sessions: Sessions are organized by experience level and led by AWS experts.
C. Expo: This bustling floor is where networking opportunities abound, along with hands-on conversations and interactive demos.
D. AWS Builder Labs: Here, cloud professionals and developers can experiment with AWS in a live sandbox environment.
E. Partner Experience: Learn from stories of cloud-powered innovation and how AWS partners, including Minfy, harness the power of AWS Cloud.
Tips for First-Time Attendees
For those new to the AWS re:Invent experience, here are some essential tips to ensure you make the most of your time in Vegas:
A. Book Your Sessions Early: The 2023 event will have a mobile app for scheduling sessions. Book your sessions as early as possible, as popular ones tend to fill up quickly.
B. Overflow rooms: If you can’t get into a session, look out for overflow rooms - they have a large screen and headphones for you to watch the sessions that are taking place. Some of the overflow rooms will have multiple screens showing different sessions so you can session hop just by walking a few steps!
C. Plan Your Accommodations: Given the vast event space, consider booking a hotel close to the venues where you plan to spend the most time.
D. Network Aggressively: These events are fantastic for formal and informal networking. Don't be shy; introduce yourself, wear some eye-catching swag, and even schedule meetings in advance.
E. Expect Crowded Shuttles: AWS runs shuttle buses, especially during busy times. Avoid getting into shuttle buses at peak time. We’d urge you to consider using one of the faster, albeit more expensive options (Rail, Uber, Lyft, etc). Comfortable shoes are your best friend for navigating the conference.
F. Explore Vegas: While AI and the cloud are fascinating, take some time to explore Las Vegas itself. Whether it's dining at a special restaurant or visiting art museums, there's plenty to experience in the city.
Book a Meeting Space
One of the standout features of AWS re:Invent 2023 is the availability of bookable meeting spaces. From November 27th to November 30th at the Encore hotel, you can choose from a variety of reception and meeting room options to facilitate productive discussions and collaborations. Learn more. [Click here to book]
What is AWS re:Invent?
AWS re:Invent is often described as "the most transformative event in tech," inviting participants to "get inspired and rethink what's possible." With over a decade of history, this event delves into all things cloud computing, covering virtually every aspect of technology.
Interesting tidbit: re:Invent is not just a conference; it's also the name of a 37-story office building at Amazon's Seattle headquarters. However, the event came before the building, with the latter opening its doors in 2019. The views from there must be incredible!
What is Minfy Looking forward to in re:Invent 2023
Here are our top picks in sessions that will excite AI Solutions and Cloud Native players:
A. Adam Seplisky - Chief Executive Officer, Amazon Web Services, Keynote, TUE., NOV. 28 | 8:30 AM – 10:30 AM
B. Dr. Swami Sivasubramanian, Vice President of Data and AI, AWS, Keynote, WED., NOV. 29 | 8:30 AM – 10:30 AM
C. Dr. Ruba Borno, Vice President, AWS Worldwide Channels and Alliances, Keynote, WED., NOV. 29 | 3:00 PM – 4:30 PM
D. Dr. Bratin Saha, Vice President of AI & ML, AIM245-INT | Innovate faster with generative AI, WED., NOV. 29 | 1:00 PM – 2:00 PM
E. G2 Krishnamoorthy, Vice President of Analytics, ANT219-INT | Data drives transformation: Data foundations with AWS analytics, THUR., NOV. 30 | 2:00 PM – 3:00 PM
F. Francessca Vasquez, Vice President of Professional Services, ARC217-INT | From hype to impact: Building a generative AI architecture, WED., NOV. 29 | 11:30 AM – 12:30 PM
G. Dilip Kumar, Vice President, AWS Applications, BIZ225-INT | C-suite leaders talk generative AI and applications, TUE., NOV. 28 | 5:00 PM – 6:00 PM
H. Mai-Lan Tomsen Bukovec, Vice President, Technology, AIM250-INT | Putting your data to work with generative AI, THUR., NOV. 30 | 12:30 PM – 1:30 PM
I. Shaown Nandi, Director, Technology and Strategic Accounts, AIM248-INT | Unlocking the industry potential of generative AI, WED., NOV. 29 | 4:00 PM – 5:00 PM
J. Nandini Ramani, Vice President of Monitoring & Observability, COP227-INT | Cloud operations for today, tomorrow, and beyond, MON., NOV. 27 | 10:30 AM – 11:30 AM
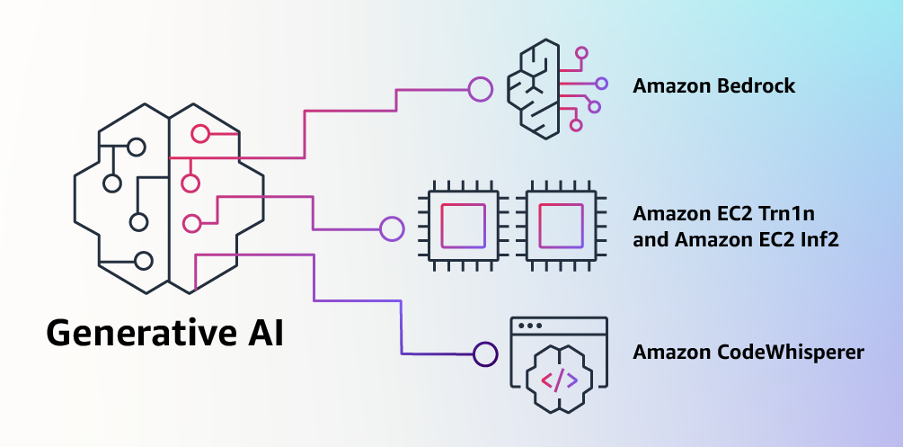
Don't miss out on sessions on LLM-related architectures, LLM use cases, Generative AI DevTools.
This year we are looking forward to a bunch of updates in AI, Modernisation, Databases and Operations.
Highlights from AWS re:Invent 2022
To whet your appetite for what's to come in 2023, let's take a quick look back at some of the major announcements from AWS re:Invent 2022.
Here are a few highlights that caught our attention:
A. New AWS Local Zones: Introduced in four new urban areas, including Buenos Aires (South America) and Copenhagen, Helsinki, and Muscat (EMEA).
B. Amazon Redshift Enhancements: Enhancements to Amazon Redshift to make data warehousing more secure and reliable.
C. Amazon Security Lake: A new service that centralizes security data from cloud and on-premises sources into a purpose-built data lake, enabling central security data management and data normalization.
D. Updates to Amazon Transcribe: Now offering real-time analytics during live calls, particularly useful for customer experience improvements.
E. AWS Wickr: An enterprise communications tool with end-to-end encryption built in.
F. New Instance Families for Amazon EC2: Focusing on General Purpose, Compute Optimized, and Memory-Optimized instances, along with new instance types in development.
G. New Features in Amazon Aurora and Amazon RDS: Including fully managed blue/green deployments with MySQL compatibility.
H. Amazon SageMaker Enhancements: New PDF features, shadow tests, new notebooks, ML governance tools, and the AWS Machine Learning University year-round program.
I. CloudWatch Upgrades: Including Amazon CloudWatch Logs, with new capabilities to detect and protect sensitive log data in transit, and Amazon CloudWatch Cross-Account Observability, enabling you to search, analyze, and correlate cross-account telemetry data.
AWS re:Invent is a massive event, and with a company as extensive as AWS, it's challenging to keep track of every single announcement.
Join Minfy at re:Invent 2023
As we gear up for AWS re:Invent 2023, be sure to mark your calendar and connect with Minfy leaders. Discover how we can help you optimize your AWS experience and navigate the world of AI and cloud computing with confidence. We look forward to seeing you in Las Vegas!
 Go to Swayam
Go to Swayam