 Go to Swayam
Go to Swayam- Home
- About
- Consulting
- Services
- Minfy Labs
- Industries
- Resonances
- Careers
- Contact
As large language models (LLMs) continue to push the boundaries of natural language processing, a significant challenge arises keeping their knowledge current and relevant in a rapidly evolving world. While traditional language models excel at generating coherent text, their knowledge is limited to the static training data they were exposed to, leaving them ill-equipped to handle dynamic, real-time information needs. Enter retrieval augmented generation (RAG), a novel approach that combines the generative power of LLMs with the ability to retrieve and incorporate relevant information from external data sources during inference. This blog post will delve into the technical mechanisms behind RAG, exploring its architecture, components, and implementation details, accompanied by code examples to illustrate its practical application.
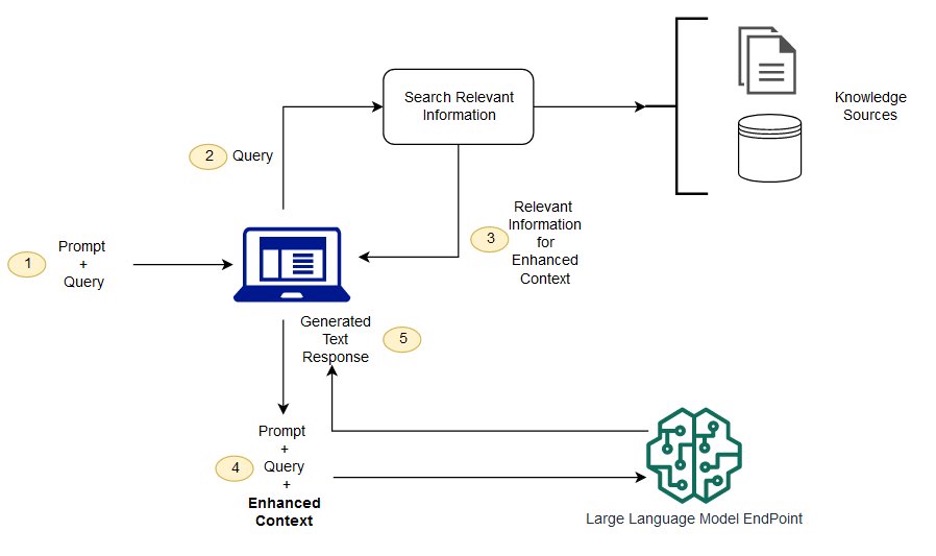
https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-foundation-models-customize-rag.html
In RAG, the external information used to augment user queries and prompts can originate from diverse data sources like document repositories, databases, or APIs. Retrieval-Augmented Generation (RAG) optimizes the output of a large language model by integrating references from an authoritative knowledge base beyond its initial training data. Large Language Models (LLMs) are trained on extensive datasets and utilize billions of parameters to generate original content for tasks such as question answering, language translation, and text completion.
Before diving into RAG, it's crucial to understand the traditional language modeling paradigm and its limitations. Language models are typically trained on vast datasets of text in a self-supervised manner, learning statistical patterns and accumulating knowledge encoded in that training data. During inference, these models generate text based solely on their internalized knowledge from training, without any external data retrieval. While this approach has yielded impressive results in various natural language tasks, it suffers from several inherent limitations:
Knowledge Staleness: The model's knowledge is frozen at the time the training data was collected, potentially missing critical recent developments or updates.
Knowledge Bottlenecking: With model sizes ranging from billions to trillions of parameters, it becomes infeasible to store all relevant knowledge directly in the model weights.
Single-Shot Learning: Once training is complete, the model cannot easily learn or incorporate new knowledge without undergoing full retraining, which is computationally expensive and time-consuming.
These limitations hinder the ability of LLMs to provide up-to-date and comprehensive information, particularly in rapidly evolving domains or scenarios where real-time data access is crucial.
RAG addresses these limitations by introducing an additional retrieval component that allows LLMs to query and incorporate relevant information from external data sources during the text generation process. This additional context can help the model stay current, augment its knowledge, and produce more factual and up-to-date outputs. The RAG architecture consists of three main components:
Encoder: This component is responsible for encoding the input query or prompt into a high-dimensional vector representation using the pre-trained LLM's encoder.
Retriever: The retriever component uses the encoded query vector to retrieve relevant documents, passages, or data entries from an external corpus. This can be achieved through various techniques, such as dense vector search or sparse keyword matching.
Decoder: The LLM's decoder attends to the augmented context, which consists of the original query concatenated with the top-k retrieved pieces of information. The decoder then generates the final output text, synthesizing the model's internalized knowledge with the retrieved context.
This architecture allows RAG to leverage the strengths of both LLMs and external data sources, resulting in more up-to-date and comprehensive generated outputs.
One of the key components of RAG is the retriever, responsible for efficiently searching and retrieving relevant information from external corpora. A popular approach for implementing this component is through dense vector retrieval, where the query and documents are encoded into high-dimensional vector representations, and similarity search is performed in this vector space.
Here's an example of how to perform dense vector retrieval using PyTorch, FAISS (a library for efficient similarity search), and the pre-trained SentenceTransformers:
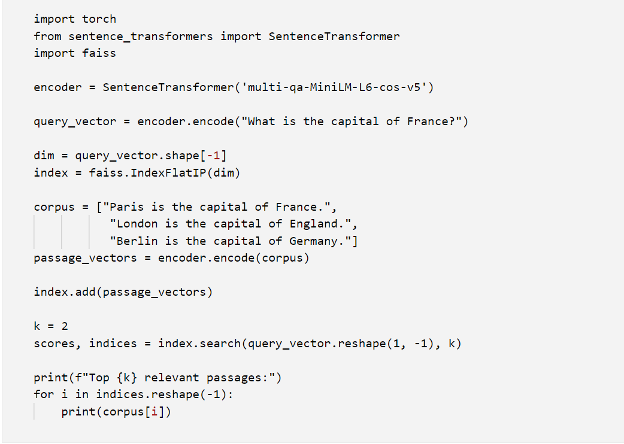
In this example, we first load a pre-trained SentenceTransformer encoder, which can encode both the query and passages into high-quality dense vector representations. We then create a FAISS index to efficiently store and search for these dense vectors. After encoding the query and corpus passages, we add the passage vectors to the FAISS index and perform a k-nearest neighbor search to retrieve the top-k most relevant passages for the given query. The output of this code snippet will be:

As you can see, the top retrieved passages are relevant to the query "What is the capital of France?", providing the necessary context to augment the LLM's generation.
Combining Retrieval and Generation Once the relevant information has been retrieved, the next challenge lies in effectively fusing this retrieved context with the LLM's generation capabilities. Several fusion strategies have been proposed and explored in RAG systems:
Concatenation-based Fusion: In this approach, the retrieved passages are simply concatenated with the original query to form the augmented input context. The LLM's decoder then attends to this augmented context during generation.
Attention-based Fusion: Instead of direct concatenation, this strategy involves using attention mechanisms to dynamically weight and combine the retrieved information with the LLM's internal representations during the decoding process.
For instance, attention-based fusion can be implemented by modifying the LLM's decoder to attend differentially to the retrieved passages and the original prompt during generation:

Here, prompt_vec and retrieved_vec represent the encoded vectors for the prompt and retrieved passages, respectively. The decoder's cross-attention mechanism attends to both sources during generation, allowing for more controlled fusion.
Reranking-based Fusion: Here, the LLM first generates multiple candidate outputs, which are then reranked or rescored based on their compatibility with the retrieved context, allowing for more controlled incorporation of external knowledge.
Reranking-based fusion strategies involve generating multiple candidate outputs and reranking them based on their compatibility with the retrieved context:
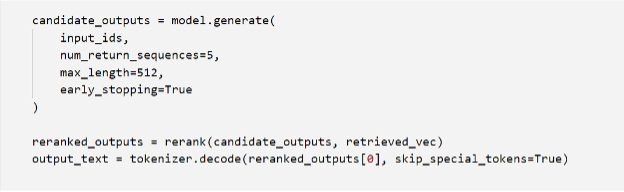
In this example, the rerank function would score each candidate output based on its compatibility with the retrieved context vectors retrieved_vec, potentially using techniques like cross-attention or learned scoring functions.
To better understand the inner workings of RAG systems, let's walk through an example that illustrates the key components and their interplay when processing a given prompt. Suppose we have a RAG system with a pre-trained language model and a retrieval component connected to a Wikipedia corpus. We'll use the following prompt as an example:

1. Query Encoding
The first step is to encode the input prompt into a high-dimensional vector representation using the pre-trained LLM's encoder:

Here, we use the pre-trained BERT model and tokenizer to encode the prompt into a vector representation query_vec.
2. Dense Vector Retrieval
Next, we use the encoded query vector to retrieve relevant passages from the Wikipedia corpus using dense vector search:

The retrieve function performs efficient nearest neighbor search in the vector space, returning the top-k most relevant passages from the indexed Wikipedia corpus.
3. Context Augmentation
The retrieved passages are then concatenated with the original prompt to form the augmented context for the LLM's decoder:

4. Language Generation
Finally, the LLM's decoder attends to the augmented context and generates the final output text, fusing the model's knowledge with the retrieved information:
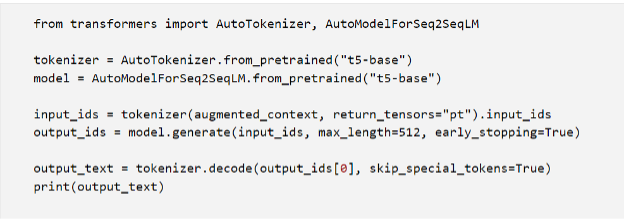
This code snippet uses the T5 sequence-to-sequence model for generation, taking the augmented context as input and generating the output text output_text. The generated output will likely be an informative response about the history of the Eiffel Tower's construction, incorporating both the LLM's knowledge and the relevant retrieved passages from Wikipedia.
As the scale and complexity of RAG systems grow, several challenges and considerations arise:
Efficient Indexing and Search: With massive external corpora, efficient indexing and retrieval techniques become crucial. Approaches like hierarchical clustering, approximate nearest neighbor search, and learned index structures can help scale billions or trillions of documents.
Retrieval Quality and Relevance: Improving the quality and relevance of retrieved information is an ongoing area of research, with approaches like dense-sparse hybrid retrieval, query reformulation, and iterative retrieval showing promising results.
Architectural Innovations: New model architectures and training strategies are being explored to better integrate retrieval and generation components, enabling more seamless fusion and knowledge grounding.
Factual Consistency and Hallucination Mitigation: As RAG systems become more capable, ensuring factual consistency and mitigating hallucinated or contradictory outputs remains a critical challenge, often addressed through techniques like consistency scoring, fact checking, and iterative refinement.
Ethical Considerations: As with any powerful AI system, RAG systems must be developed and deployed with careful consideration of ethical implications, such as potential biases in the retrieved data, privacy concerns, and responsible use of these technologies.
As language AI continues to advance, techniques like retrieval augmented generation that combine the strengths of large language models and external data access will likely play a pivotal role in building AI assistants with dynamic, ever-growing knowledge. While challenges remain in areas like efficient retrieval, knowledge grounding, and factual consistency, RAG represents a promising paradigm for keeping language models up-to-date and relevant in our rapidly evolving world.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-foundation-models-customize-rag.html
~ Author: Yasir UI Hadi

Our overburdened healthcare system leaves providers perpetually understaffed and overwhelmed — an increasingly dire situation both in India and globally. Doctors, nurses, and medical staff often work around the clock struggling to meet demand from ever-growing patient numbers [1]. While we cannot conjure more providers overnight or ignore those needing critical care, technology can help maximize efficiency for existing staff.
Minfy aims to streamline healthcare delivery to boost productivity. We offer a suite of AI-powered solutions for organizations of any size — from small clinics to major hospitals. These tools automate tedious tasks, freeing up precious staff hours for direct patient care.
Our flagship solution: an AI Discharge Report Generator creating concise, accurate summaries from complex medical records. What once took 20 gruelling minutes per patient [2] now requires just seconds, translating to over 30 rescued hours weekly for a typical hospital's discharge workflow.
The solution takes into consideration everything from admission and follow-ups to lab results and radiology, distilling volumes of data down to salient points. It then auto-populates a shareable summarized patient discharge report including treatment and diagnosis specifics, medications, post-discharge care plans and more — complete with custom formatting.
This game-changing efficiency allows doctors, nurses and technicians to redirect their focus toward broader care coordination, personalized treatment and critical decision making. With intuitive tools like discharge report automation, care providers can devote their precious skills more fully to patient interactions rather than paperwork.
AI handles the drudgery, while human insight guides compassion, Minfy’s vision of bionic journey. Combined properly, technology and medical expertise create a potent formula for Healthcare's immense challenges today and tomorrow. Our solutions ease overburdened systems to empower providers and enhance outcomes - one automated task at a time.
The heart of any solution lies in first deeply understanding the problem. Here, we saw providers burning out, overwhelmed creating discharge summaries - draining hours from pressing patient needs. Our solution uses AI to transform time-sinking paperwork into fast, personalized reports. Let’s dive deeper into;
The Problem: Creating discharge reports is extremely time-consuming for healthcare providers. Doctors spend about 30 hours every week putting these complex reports together by gathering lengthy records and test results. This manual and tiring process takes away precious time that doctors could instead directly spend caring for patients.
The Solution: We built an automated reporting system, powered by machine learning, that reduces reporting time from 20 minutes to less than 1 minute per patient. This frees up providers to deliver top-quality care vs. hunching over keyboards. Our 3-phase process transforms workflow efficiency:
1) Data Ingestion - Patient medical records across formats are pre-processed and fed into the system in a machine-readable structure optimized for AI.
2) Natural Language Generation - We fine-tuned a state-of-the-art large language model on real-world health data for accurate report drafting on custom HL7 FHIR compliant templates.
3) Automated Pipeline - Providers can now instantly generate summarized discharge reports with all salient details via our solution.
The core data powering our discharge report generator originates from hospitals' electronic health record (EHR) systems. This includes structured, unstructured and semi-structured data spanning admission assessments, follow-ups, progress notes, lab tests and radiology reports. Essentially, the complete picture of a patient's stay.
These records are securely transferred to Amazon S3 on a regular basis for processing. Text Documents, PDFs and scanned images first undergo optical character recognition (OCR) for text extraction. An ETL pipeline then handles validating, normalizing and cleaning all data to prepare it for analytics, while ensuring adherence to healthcare regulations around privacy, HIPAA Compliance.
Specifically, an automated workflow leverages Amazon Textract for OCR, Amazon Glue for crawling and cataloguing incremental data, and Glue ETL jobs for transformations. The outputs feed into a refined, analytics-ready dataset in an access-controlled S3 bucket after stripping personally identifiable information (PII) to respect privacy.
In the end, we gather disorderly patient data, wrangle it into a consistent structured format, and deliver cleansed, compliant and meaningful inputs to downstream AI systems - providing the foundation for fast discharge report generation.
We fine-tuned an open-source Large Language Model (LLM) to create discharge summaries from medical notes in HL7 FHIR format to enable interoperability between healthcare systems. Our goal is to automatically summarize relevant medical history, lab tests, procedures, follow-up instructions and medications from the unstructured doctors' notes.
We started with the Mistral 7B LLM as our base model due to its 7.3 billion parameter size and ability to generate high quality summaries while having lower latency for a model of this size. We fine-tuned this model on custom dataset to adapt it to the medical domain using Parameter-Efficient Fine-Tuning (PEFT) technique.

Total trainable parameters i.e. less than 1% of total parameters in Mistral 7B LLM
Finally, after carefully testing the model, it was deployed on a SageMaker endpoint to serve real-time inferences. The endpoint runs on a ml.g4dn.xlarge instance to provide a good throughput with sub-second latency for generating upto 1000 token summaries.
We implemented an automated pipeline to process medical reports and generate summarized discharge reports using our customized LLM. This pipeline utilizes several key AWS services:
An Amazon Lambda function orchestrates the workflow. This invokes a SageMaker endpoint hosting our custom LLM fine-tuned on medical text, passing the patient's reports data as input. The model analyses this text and returns a comprehensive HL7 FHIR compliant, summarized discharge report to the Lambda.
The Lambda then performs postprocessing. The summarized text is formatted into a shareable PDF and customized with hospital branding and relevant metadata. This polished report is uploaded to an encrypted Amazon S3 bucket for compliance and easy access. A unique, time-limited URL allows medical staff like physicians to securely view and download reports on-demand.
On the frontend, our intuitive web portal allows two key options: Healthcare staff can manually upload new documents or search historical records by patient ID to automatically process reports already within system. Users can preview reports before downloading locally for further review or signatures before being provided to patients.
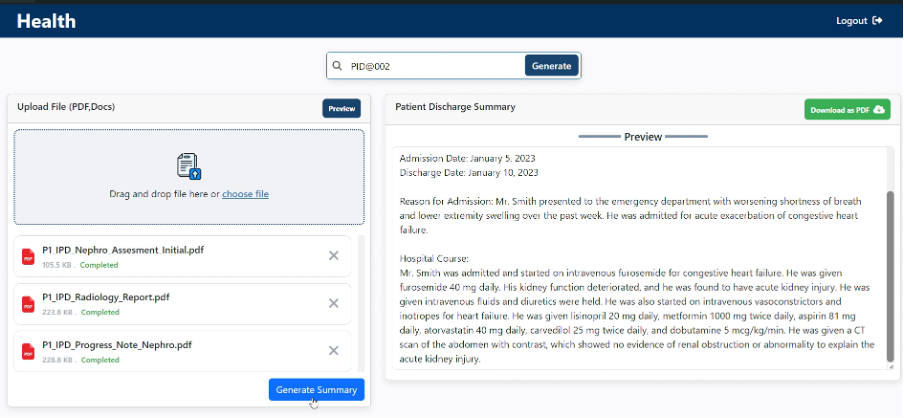
Web-Application UI to Manually Upload Documents
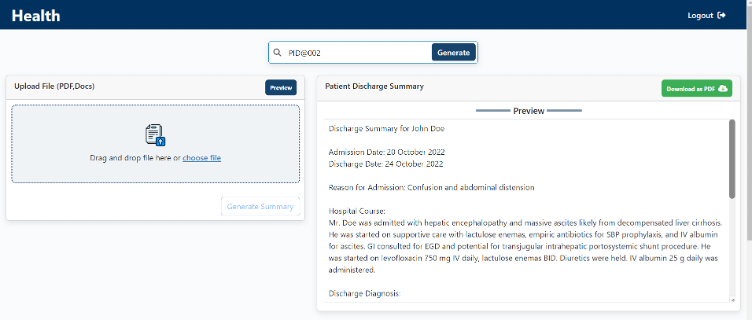
Web-Application UI to Search Historical Records by Patient ID

Downloaded Discharge Report View
Our automated discharge report solution showcases the immense potential of thoughtfully leveraging AI and cloud technology to enhance healthcare outcomes. By tackling a point of major inefficiency – the tedious task of creating discharge summaries – we have successfully demonstrated multiple high-impact capabilities with this solution:
1) Natural language generation fine-tuned on real-world data to auto-draft accurate, structured summaries in less than a minute rather than hours.
2) Seamless integration of leading services like Amazon Textract, SageMaker, Lambda and S3 to ingest, process, analyse and securely deliver data.
3) User-friendly web portal that allows providers to instantly search records and download compliant reports with custom formatting and branding.
4) Over 90% reduction in reporting time, freeing up providers to better utilize their specialized skills and human insight.
5) Template for expanding automation across other document-intensive hospital workflows.
The bottom line - our solution effectively combines the strengths of both powerful AI and dedicated medical staff to elevate care quality. We ease the data-driven work to reveal key insights faster, while leaving the compassionate critical thinking to professionals best qualified for it.
~ Author: Gaurav Lohkna
This website stores cookie on your computer. These cookies are used to collect information about how you interact with our website and allow us to remember you. We use this information in order to improve and customize your browsing experience and for analytics and metrics about our visitors both on this website and other media. To find out more about the cookies we use, see our Privacy Policy. If you decline, your information won’t be tracked when you visit this website. A single cookie will be used in your browser to remember your preference not to be tracked.