 Go to Swayam
Go to Swayam- Home
- About
- Consulting
- Services
- Minfy Labs
- Industries
- Resonances
- Careers
- Contact
Connecting with MongoDB using Glue Connector:
Difficulty in establishing a connection between AWS Glue and MongoDB using the Glue connector due to configuration complexities and compatibility issues. The AWS Glue connector was ineffective due to issues with Java truststore and SSL MongoDB connection.
To address this challenge, we have leveraged AWS Glue for Spark to establish connectivity between MongoDB and AWS Glue. This allowed us to bypass the complexities and compatibility issues associated with the Glue connector. Instead, we utilized the script provided in the AWS Documentation within our ETL process.
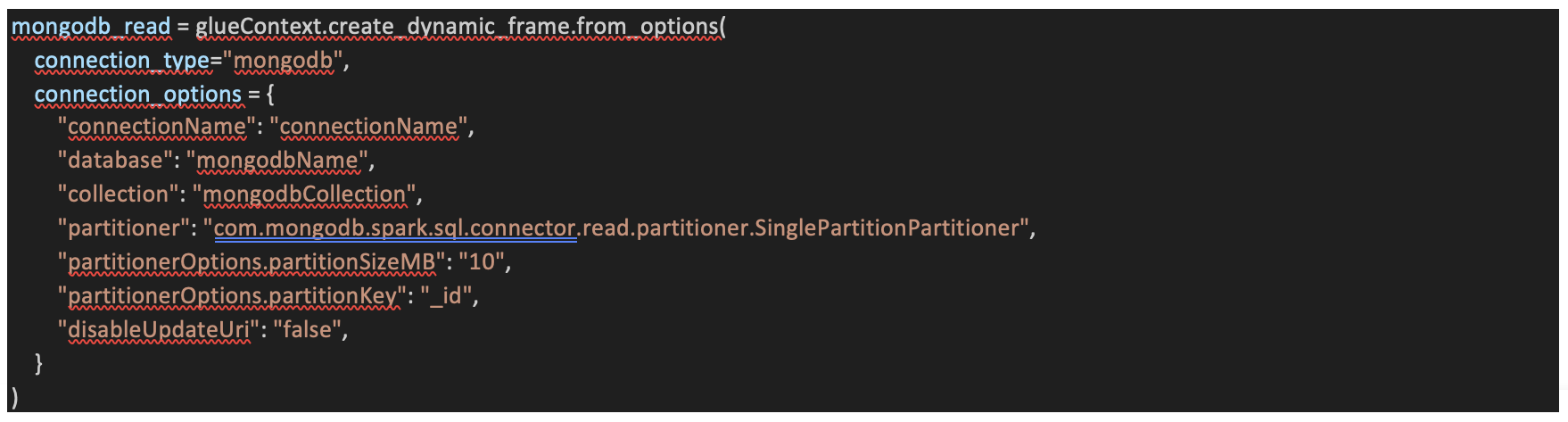
This script configures the connection by specifying parameters such as connection name, database, collection, partitioner, partition size, partition key, and update URI status. It enables Glue to interact seamlessly with MongoDB, overcoming connection challenges effectively.
Configuring ETL Script with Manual Timestamp for Incremental Data Sync:
In the AWS Glue ETL script configuration, the Bookmark feature did not cater to our specific use case, causing limitations in achieving incremental data synchronization. Enabling the Bookmark feature resulted in pulling full data instead of solely incremental data. Furthermore, it was noted that Bookmarks are supported only in S3 and JDBC data sources, further restricting our options for incremental data synchronization.
To address this challenge, we opted to manually manage the timestamp for incremental data synchronization within the ETL script. By incorporating custom logic to track and update timestamps, we effectively ensured the synchronization of only the new or modified data since the last synchronization. This approach circumvented the limitations posed by the default Bookmark feature, enabling us to achieve precise and efficient incremental data synchronization as per our use case requirements.
Optimizing Partitioning Structure to Reduce File Overhead:
When utilizing the Parquet file format and partitioning data in AWS Glue with Spark, the default behavior results in the creation of multiple files per partition. Each unique combination of partition column values generates a separate directory (partition) in the storage system. Within these partition directories, numerous small files are created to store data corresponding to the specific combination of partition column values. However, to align with customer's preference to minimize storage overhead and manage the high volume of data efficiently we've opted for storing data in single file.
To mitigate this challenge, we implemented the concept of coalescing within the Glue ETL script. By coalescing the DataFrame output before writing to the S3 destination, we ensured that data within each partition was consolidated into a single file. This optimization effectively reduced storage overhead and enhanced the efficiency of data retrieval and management. Consequently, storing a single file in unique partition paths streamlined the data storage process, improving resource utilization and facilitating smoother data operations within the AWS Glue environment.
Schema Harmonization for Mismatched Data Structures:
• Integrating incremental data, comprising both new and updated records, with existing datasets posed a significant challenge due to schema mismatches. These discrepancies primarily stemmed from variations in data structures across different files, such as differing array types (e.g., array of strings vs. array of structs) or discrepancies in basic data types (e.g., StringType vs. LongType).
• To address this challenge, a custom data processing function was developed to harmonize schemas and facilitate seamless data integration. The function analyzed the schema of incoming dataframes, identifying columns with mismatched array structures. Subsequently, it transformed the array columns to conform to a unified schema, ensuring consistency across datasets.
• The find mismatch array function identified columns with mismatched array structures, enabling targeted schema transformation.
• The transform array columns function harmonized array columns by converting data to match the desired schema, handling both structural discrepancies and basic data type mismatches.
• The process_data function leveraged these schema harmonization techniques to merge incremental data with existing datasets effectively. By dynamically adjusting array structures and data types, it ensured compatibility and consistency across datasets, facilitating smooth data integration processes.
Handling Duplicate Entries During Incremental Data Merge:
• During the merging of incremental data with existing datasets, the possibility of duplicate entries arose, particularly when updated rows were present in the incremental data. This duplication occurred post-merge, leading to redundancy within the merged dataset.
• To address this challenge and maintain the integrity of the merged dataset, a solution was devised to identify and remove duplicate entries based on the latest modified timestamp. By querying the dataset for the latest modified timestamp entry post-merge, redundant rows were pinpointed and eliminated, ensuring data consistency and eliminating duplication.
• After merging the incremental data with the existing dataset, a query was executed to retrieve the entry with the latest modified timestamp. This was accomplished using the following SQL query:

• In this query, the `ROW_NUMBER ()` window function is utilized to assign a sequential row number to each record within a partition, which is determined by the `_id` field. The records are ordered based on the modified time column in descending order, ensuring that the row with the latest modification timestamp receives row number of 1.
• By filtering the results to include only rows where `row_num` equals 1, the query effectively selects the most recent version of each record, thereby eliminating duplicates and maintaining the integrity of the merged dataset.
Note: This query is executed to create a dataset in Amazon QuickSight, not to modify data stored in Amazon S3. The purpose is to ensure that only the latest version of each record is included in the dataset used for visualization, thereby removing duplicates and enhancing data accuracy in the reporting process.
Resolving Data Ambiguity: Overcoming Inconsistencies in QuickSight Dashboard Filters:
• In our QuickSight dashboard, inconsistency in data regarding the relationship between facility_id and facility_name resulted in ambiguity and incorrect data representation, especially when using facility_name as a filter. Despite the expectation of a unique facility_name for each facility_id, discrepancies arose where a single facility_id was associated with two slightly different facility_names.
• To address this issue, we implemented a solution within QuickSight by creating a calculated field. This calculated field explicitly specified the specific facility_name for each unique facility_id, ensuring that there was no multiple facility_names associated with a single facility_id. By adopting this approach, we successfully resolved the ambiguity and ensured accurate data visualization and analysis in our QuickSight dashboard, particularly when using facility_name as a filter.
Solution Architecture.
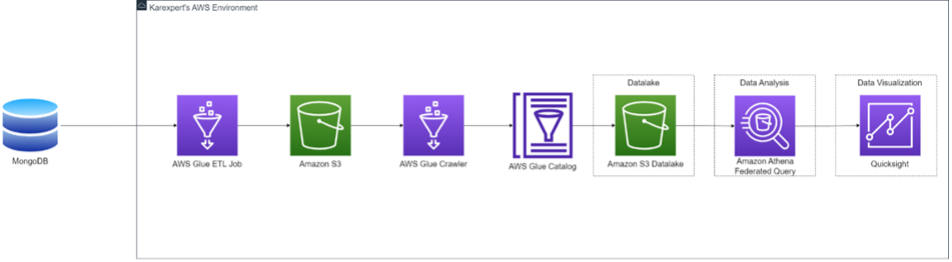
The solution architecture details the orchestration of AWS services that collectively manage the data workflow. The structure ensures efficient data processing from the initial extraction in MongoDB to the final visualization in Amazon QuickSight.
A secure connection between MongoDB and AWS is facilitated through AWS Glue for Spark. In AWS Glue version 4.0 and later, you can utilize AWS Glue to read from and write to tables in MongoDB and MongoDB Atlas.
• AWS Glue jobs are used to perform Extract, Transform, Load (ETL) processes on the extracted data, ensuring compatibility with visualization tools.
• Data undergoes transformation to prepare it for analysis, enabling seamless integration with visualization tools such as Amazon QuickSight.
• Post-transformation, the data is organized within an S3 bucket to create a data lake, structured to facilitate analytical needs, and enable in-depth data exploration.
• The data lake architecture ensures scalability and flexibility, allowing for the storage of large volumes of data in a cost-effective manner.
• Amazon QuickSight utilizes AWS Glue Data Catalog tables as a metadata repository and leverages Amazon Athena for querying data stored in the S3 data lake. QuickSight connects to Athena as a data source, allowing users to create interactive dashboards and reports for business intelligence and data-driven decision-making.
• QuickSight's intuitive interface enables users to explore and analyze data effortlessly, empowering stakeholders to derive actionable insights from the data.
• The solution architecture orchestrates AWS services effectively to manage the data workflow, ensuring efficient data processing from MongoDB extraction to visualization in Amazon QuickSight.
Furthermore, the solution description provides detailed insights into the implementation of various functions within the ETL script:
• The ETL script performs a range of critical functionalities, including extracting collection and database information from a csv file stored in an S3 bucket, configuring environment-based settings dynamically based on the provided environment name as a job parameter, and seamlessly handling incremental data extraction, even in scenarios involving errors like schema mismatches. This comprehensive approach ensures efficient and reliable data processing across different environments.
• It establishes connections to MongoDB and orchestrates data extraction, leveraging AWS Glue to convert the extracted data into DataFrame format for further processing. We opted not to use DynamicFrame for this purpose since some of the inbuilt functions offered in handling DataFrames are not available with DynamicFrame.
• Timestamp formatting and partitioning functionalities are incorporated to adjust timestamps to reflect the UTC+5:30 timezone and optimize data storage in S3 using Parquet format.
• Additional functions, such as sending emails, updating Glue crawler targets, and managing timestamp CSV files on S3, contribute to the robustness and efficiency of the data processing pipeline.
In summary, the comprehensive solution architecture and ETL job showcase the seamless integration of AWS services and custom functionalities to address specific project requirements, enabling organizations to derive valuable insights from their data and drive informed decision-making processes.
1. Collection and Database Information:
Extracts the collection name, MongoDB database name, and timestamp column from the provided row.

2. Environment-Based Configuration:
Checks if the specified environment is one of the supported environments ('env1’, 'env2', 'env3'). Exits the function if it's unsupported.

3. Environment-Specific Connection Settings:
Sets the connection parameters (connection string, username, password, S3 base path) based on the selected environment.

4. Checking for Incremental Extraction:
Checks if the timestamp file exists in S3 for the specified collection, determining whether to perform incremental or full data extraction.

5. Environment Validation:
Validates if the specified environment is part of the paths to crawl. Exits the function if not.

6. Incremental Extraction Logic:
Branches into either incremental or full data extraction based on the previous check.

7. MongoDB Connection Options:
Defines the MongoDB connection options, including connection URI, database, collection, username, password, and any specific aggregation pipelines for incremental extraction.
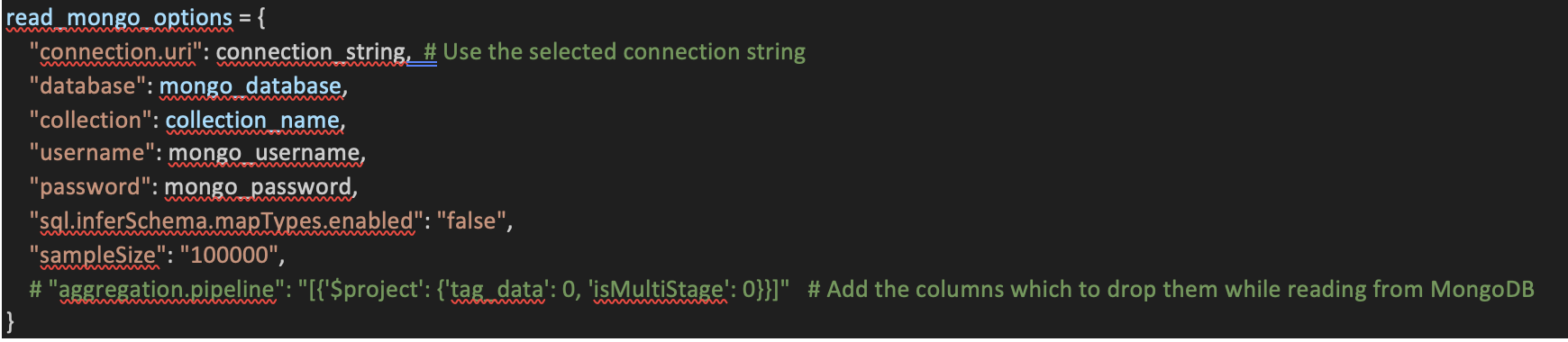
8. Connection to MongoDB and Data Extraction:
Establishes a connection to MongoDB using AWS Glue, applying the specified connection options, and converts the dynamic frame to a DataFrame.

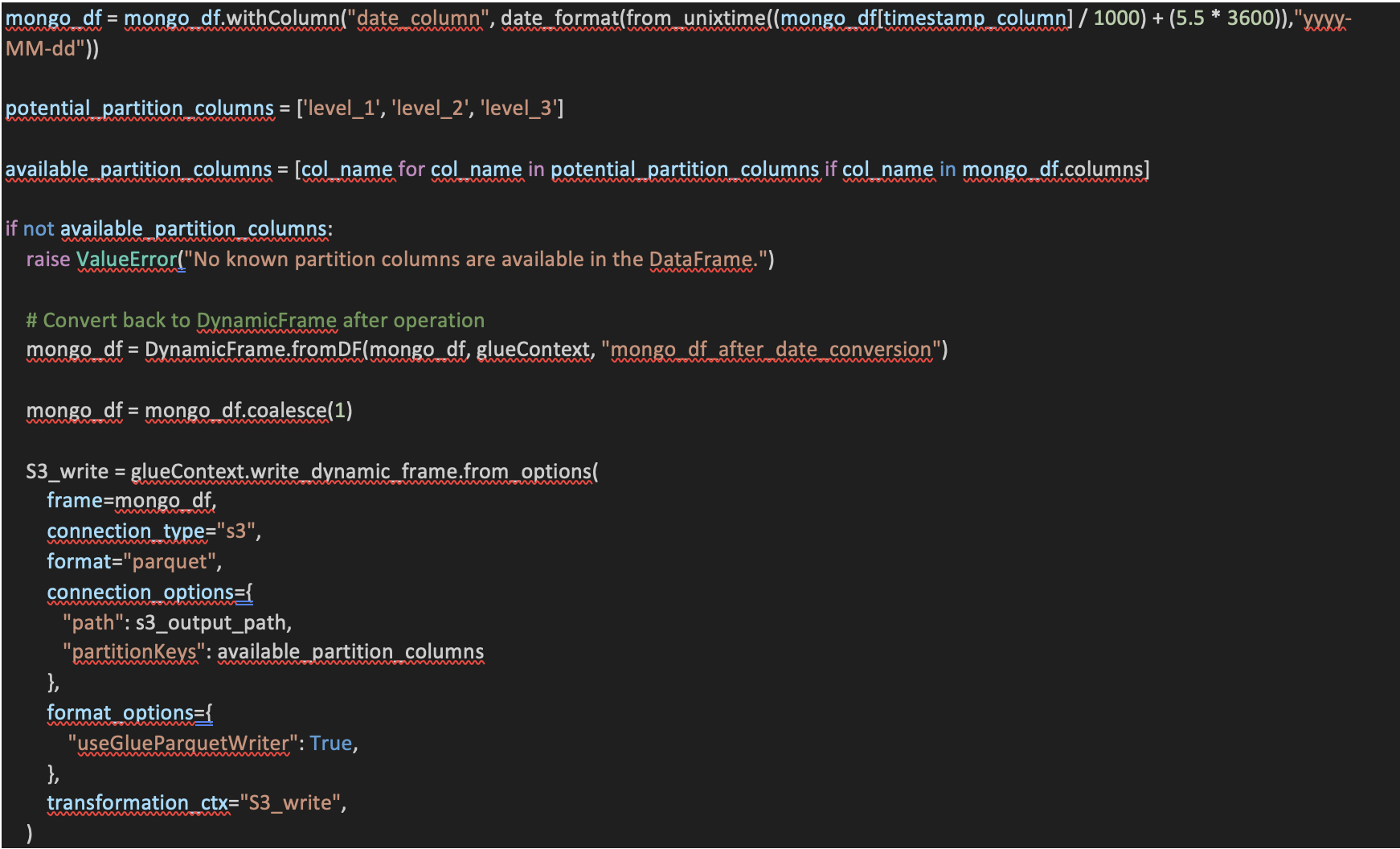
9. Timestamp Formatting and Partitioning:
• Adjusts timestamps to reflect UTC+5:30 timezone before partitioning and storing data.
• Utilizes the `date_format` and `from_unixtime` functions to format timestamps into a human-readable format, considering the UTC offset.
• Defines partition structure with potential columns such as 'date', 'id1', and 'id2'.
• Raises a ValueError if no recognizable partition columns are available in the DataFrame.
• Converts the DataFrame back to DynamicFrame to maintain compatibility with AWS Glue.
• Optimizes performance by coalescing the DataFrame into a single partition before writing it to storage.
• Writes the transformed data to an S3 bucket in Parquet format, ensuring the specified partition keys are applied to the storage structure.
10. send_email Function:
• This function is designed to send an email using Amazon Simple Email Service (SES)
• It takes a subject and body as input and uses the `ses_client` to send an email to the specified recipient
• It prints the message ID if the email is sent successfully and handles errors if any occur during the email sending process.
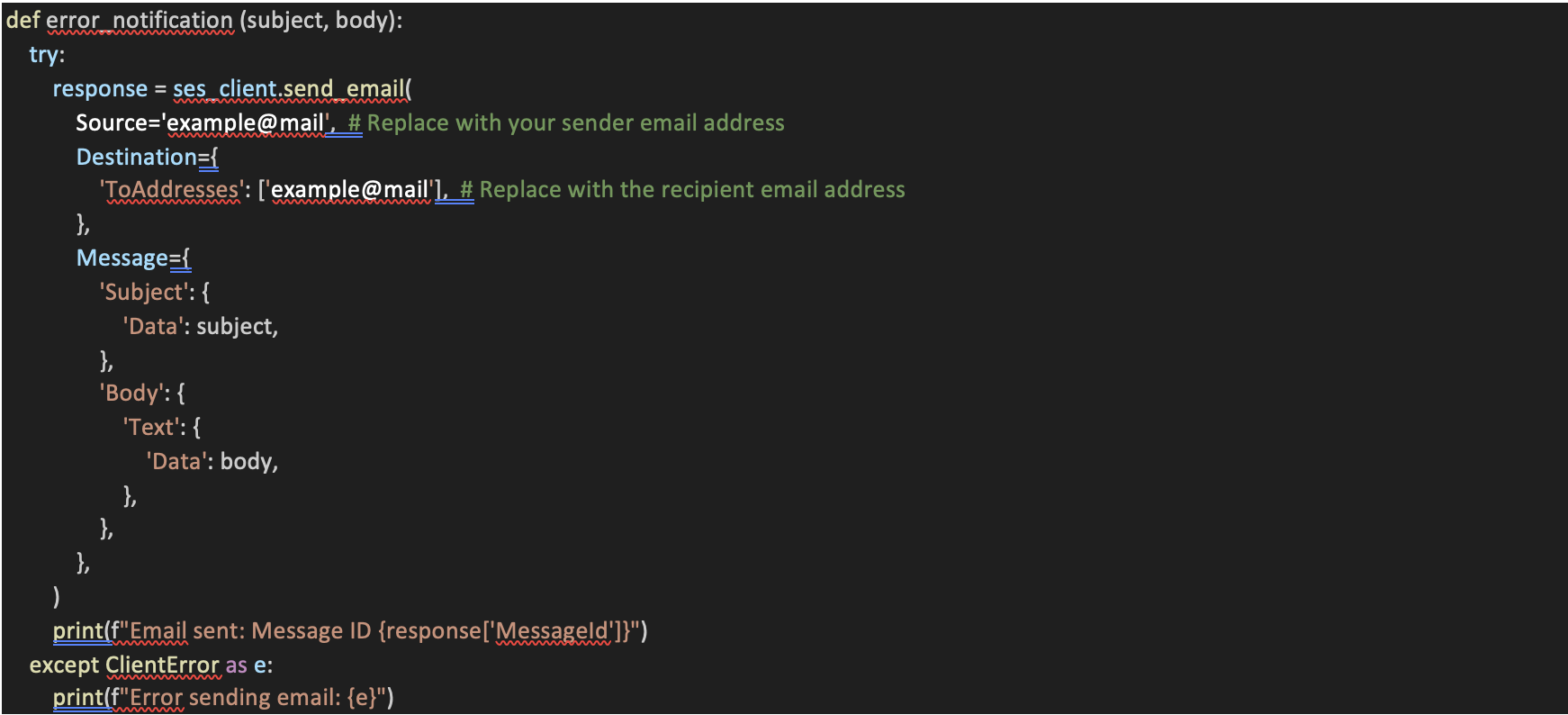
11. update_crawler_targets Function:
• This function is part of AWS Glue, a service for preparing and loading data into data stores.
• It updates the targets of an existing Glue Crawler with new S3 paths. It expects the crawler's name, list of paths, and the database name.
• The function converts the paths into the format expected by the Glue API and then calls `update_crawler` to apply these changes to the specified crawler.
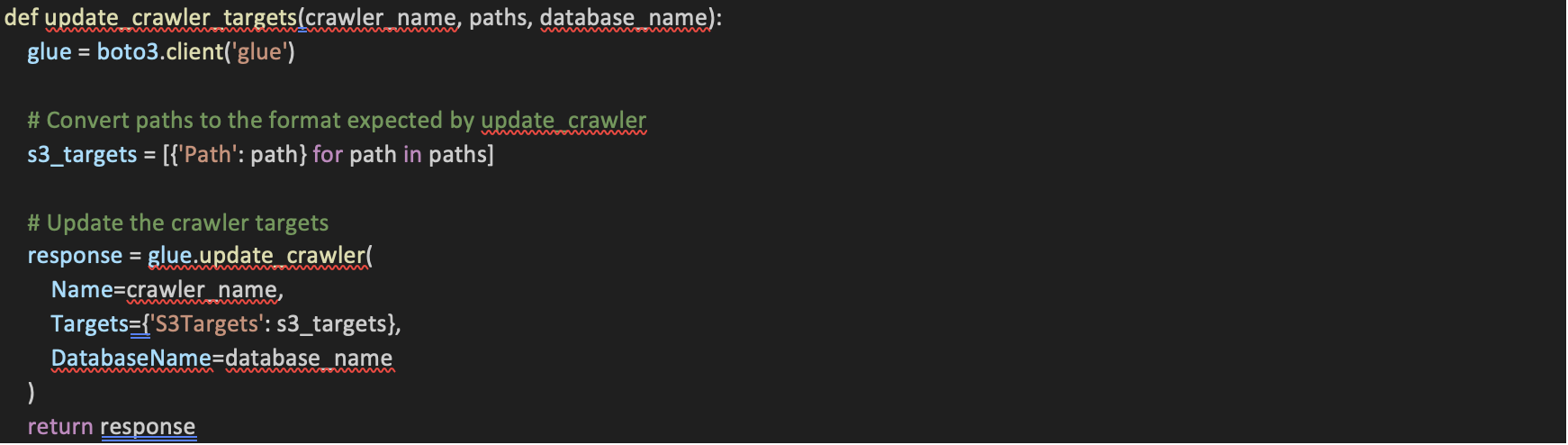
12. get_last_processed_timestamp Function:
• This function retrieves the last processed timestamp for a given database and collection.
• It constructs the S3 file path based on the database and collection names and attempts to read a CSV file from S3.
• If the file exists, it reads the CSV and returns the last timestamp from the DataFrame. If the file is not found, it returns to `None`.
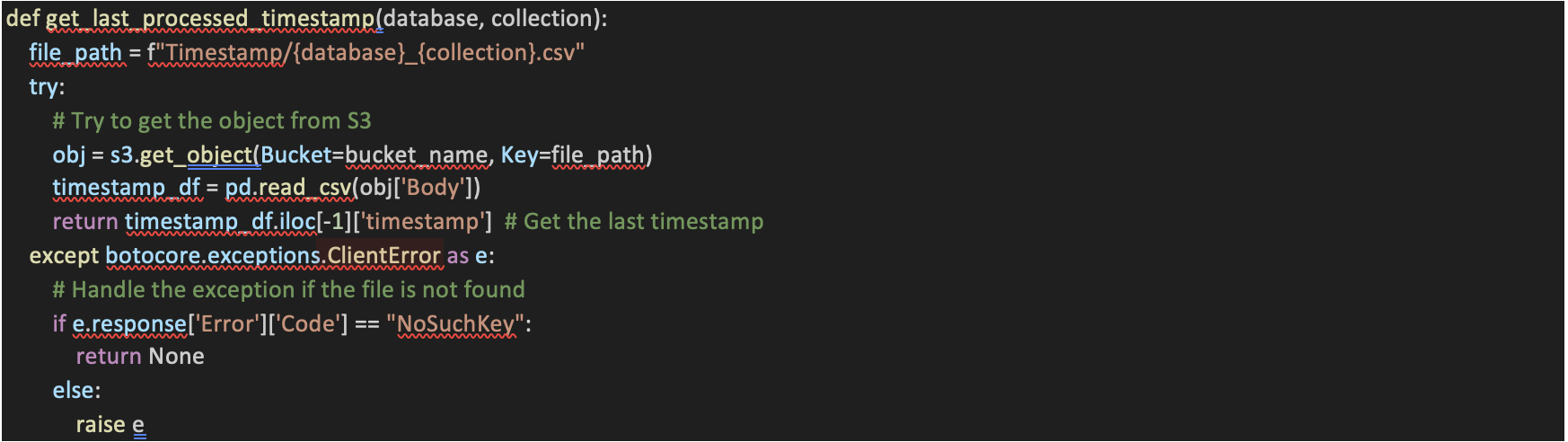
13. update_timestamp_csv Function:
This function is responsible for updating a timestamp CSV file stored on Amazon S3.It loads the existing CSV content (if any) from S3, appends a new timestamp to the DataFrame, and then saves the updated DataFrame back to S3.
14. extract_database_name_from_path Function:
This function extracts the database name from a given S3 path. It splits the path using the '/' character and retrieves the database name from a specific position in the resulting list, the purpose of this database is to use specified crawler which needs to be updated.

15. Glue Crawler Update and Start:
• This section of code updates and starts AWS Glue Crawlers based on the paths obtained from the `paths_to_crawl` dictionary. It filters out paths corresponding to failed collections and then groups the paths by database name.
• For each database, it calls `update_crawler_targets` to update the crawler with the new paths and then starts the Glue Crawler using `glue_wrapper.start_crawler`.
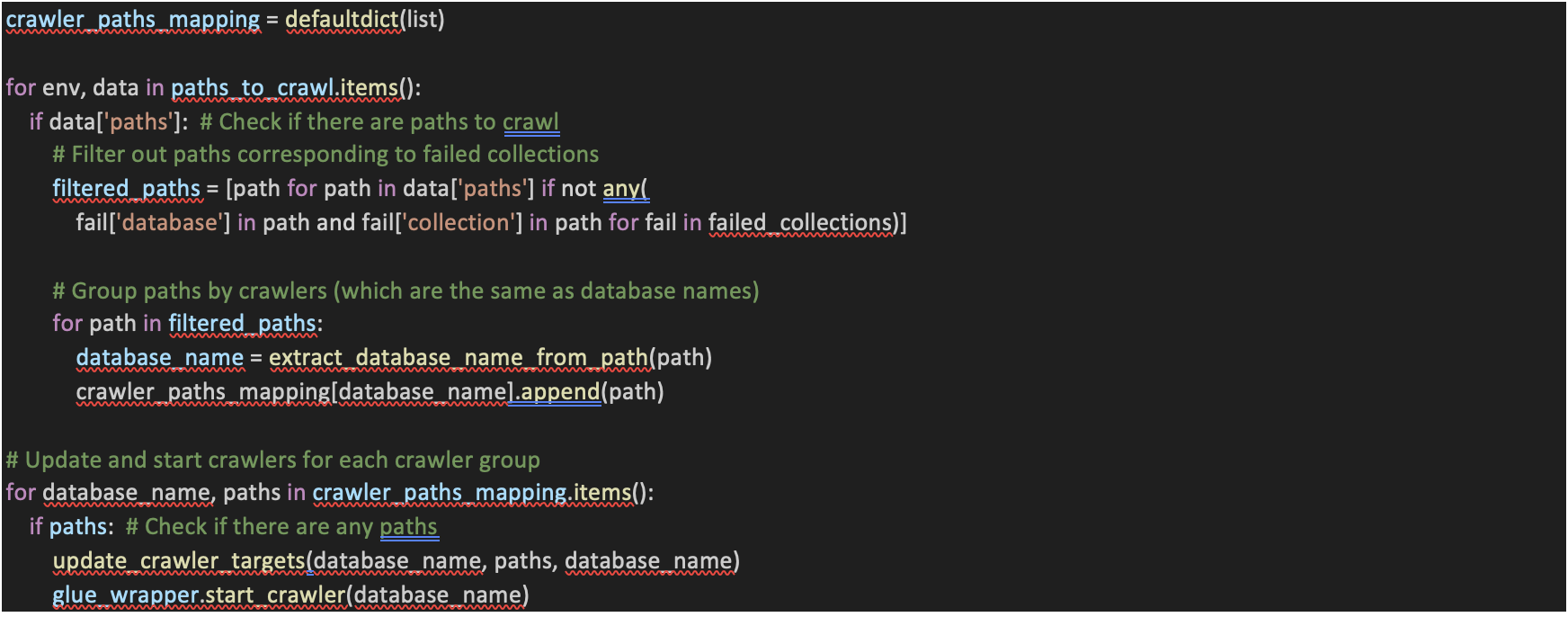
16. Glue Data Catalog Creation:
• AWS Glue is utilized to automatically discover, and catalog datasets stored in the S3 data lake.
• The Glue data catalog provides a unified metadata repository, facilitating easy data exploration and analysis.
17. Data Analysis with Athena:
• SQL-based analysis is performed using Amazon Athena to derive insights from the healthcare datasets stored in the S3 data lake.
• SQL queries are executed to generate datasets relevant to financial analysis, operational efficiency, clinical outcomes, administrative tasks, and inventory management.
18. QuickSight Visualizations:
• After the data is stored in Amazon S3 and tables are created in the AWS Glue Data Catalog, the next stage involves leveraging these tables to perform analysis and visualization.
• Using the tables registered in the Glue Data Catalog, AWS Athena is employed as a query service to interactively analyze the data. Athena enables querying data directly from S3 using standard SQL syntax, without the need for complex ETL processes.
• SQL-generated datasets are seamlessly integrated into Amazon QuickSight for visualization and dashboard creation.
• 24 Interactive dashboards are developed for each production environment, covering various subject areas such as financial analysis, operational efficiency, clinical outcomes, administrative tasks, appointment analysis, laboratory, bed occupancy, inventory management, etc.
Minfy has a repository of learnings, competencies and an enviable track record of meeting customer needs. Advice and service, solutions and responsiveness work in tandem. Begin your cloud journey, accelerate it or optimise your cloud assets. Experience business impact.

This website stores cookie on your computer. These cookies are used to collect information about how you interact with our website and allow us to remember you. We use this information in order to improve and customize your browsing experience and for analytics and metrics about our visitors both on this website and other media. To find out more about the cookies we use, see our Privacy Policy. If you decline, your information won’t be tracked when you visit this website. A single cookie will be used in your browser to remember your preference not to be tracked.