 Go to Swayam
Go to Swayam- Home
- About
- Consulting
- Services
- Minfy Labs
- Industries
- Resonances
- Careers
- Contact
As large language models (LLMs) continue to push the boundaries of natural language processing, a significant challenge arises keeping their knowledge current and relevant in a rapidly evolving world. While traditional language models excel at generating coherent text, their knowledge is limited to the static training data they were exposed to, leaving them ill-equipped to handle dynamic, real-time information needs. Enter retrieval augmented generation (RAG), a novel approach that combines the generative power of LLMs with the ability to retrieve and incorporate relevant information from external data sources during inference. This blog post will delve into the technical mechanisms behind RAG, exploring its architecture, components, and implementation details, accompanied by code examples to illustrate its practical application.
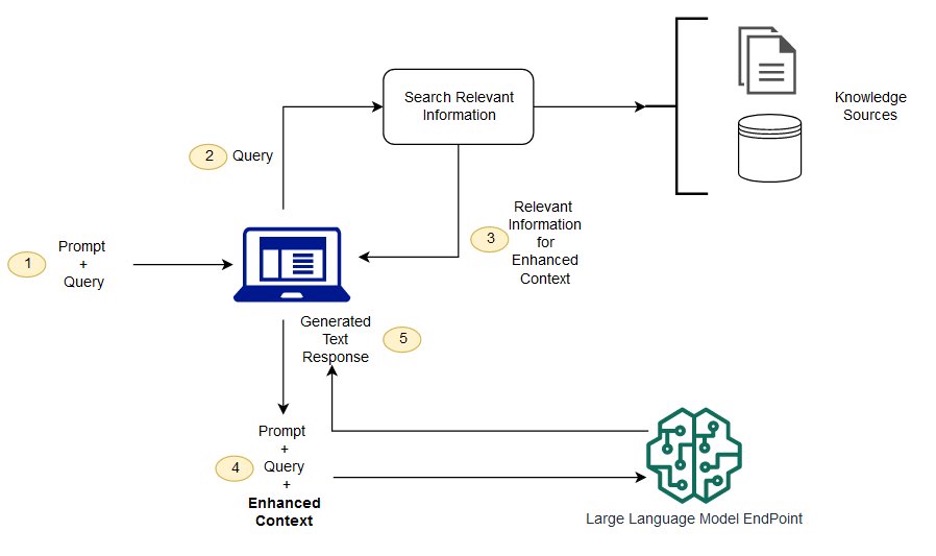
https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-foundation-models-customize-rag.html
In RAG, the external information used to augment user queries and prompts can originate from diverse data sources like document repositories, databases, or APIs. Retrieval-Augmented Generation (RAG) optimizes the output of a large language model by integrating references from an authoritative knowledge base beyond its initial training data. Large Language Models (LLMs) are trained on extensive datasets and utilize billions of parameters to generate original content for tasks such as question answering, language translation, and text completion.
Before diving into RAG, it's crucial to understand the traditional language modeling paradigm and its limitations. Language models are typically trained on vast datasets of text in a self-supervised manner, learning statistical patterns and accumulating knowledge encoded in that training data. During inference, these models generate text based solely on their internalized knowledge from training, without any external data retrieval. While this approach has yielded impressive results in various natural language tasks, it suffers from several inherent limitations:
Knowledge Staleness: The model's knowledge is frozen at the time the training data was collected, potentially missing critical recent developments or updates.
Knowledge Bottlenecking: With model sizes ranging from billions to trillions of parameters, it becomes infeasible to store all relevant knowledge directly in the model weights.
Single-Shot Learning: Once training is complete, the model cannot easily learn or incorporate new knowledge without undergoing full retraining, which is computationally expensive and time-consuming.
These limitations hinder the ability of LLMs to provide up-to-date and comprehensive information, particularly in rapidly evolving domains or scenarios where real-time data access is crucial.
RAG addresses these limitations by introducing an additional retrieval component that allows LLMs to query and incorporate relevant information from external data sources during the text generation process. This additional context can help the model stay current, augment its knowledge, and produce more factual and up-to-date outputs. The RAG architecture consists of three main components:
Encoder: This component is responsible for encoding the input query or prompt into a high-dimensional vector representation using the pre-trained LLM's encoder.
Retriever: The retriever component uses the encoded query vector to retrieve relevant documents, passages, or data entries from an external corpus. This can be achieved through various techniques, such as dense vector search or sparse keyword matching.
Decoder: The LLM's decoder attends to the augmented context, which consists of the original query concatenated with the top-k retrieved pieces of information. The decoder then generates the final output text, synthesizing the model's internalized knowledge with the retrieved context.
This architecture allows RAG to leverage the strengths of both LLMs and external data sources, resulting in more up-to-date and comprehensive generated outputs.
One of the key components of RAG is the retriever, responsible for efficiently searching and retrieving relevant information from external corpora. A popular approach for implementing this component is through dense vector retrieval, where the query and documents are encoded into high-dimensional vector representations, and similarity search is performed in this vector space.
Here's an example of how to perform dense vector retrieval using PyTorch, FAISS (a library for efficient similarity search), and the pre-trained SentenceTransformers:
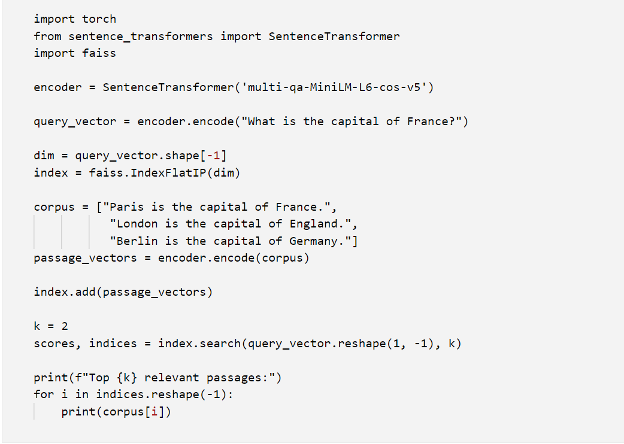
In this example, we first load a pre-trained SentenceTransformer encoder, which can encode both the query and passages into high-quality dense vector representations. We then create a FAISS index to efficiently store and search for these dense vectors. After encoding the query and corpus passages, we add the passage vectors to the FAISS index and perform a k-nearest neighbor search to retrieve the top-k most relevant passages for the given query. The output of this code snippet will be:

As you can see, the top retrieved passages are relevant to the query "What is the capital of France?", providing the necessary context to augment the LLM's generation.
Combining Retrieval and Generation Once the relevant information has been retrieved, the next challenge lies in effectively fusing this retrieved context with the LLM's generation capabilities. Several fusion strategies have been proposed and explored in RAG systems:
Concatenation-based Fusion: In this approach, the retrieved passages are simply concatenated with the original query to form the augmented input context. The LLM's decoder then attends to this augmented context during generation.
Attention-based Fusion: Instead of direct concatenation, this strategy involves using attention mechanisms to dynamically weight and combine the retrieved information with the LLM's internal representations during the decoding process.
For instance, attention-based fusion can be implemented by modifying the LLM's decoder to attend differentially to the retrieved passages and the original prompt during generation:

Here, prompt_vec and retrieved_vec represent the encoded vectors for the prompt and retrieved passages, respectively. The decoder's cross-attention mechanism attends to both sources during generation, allowing for more controlled fusion.
Reranking-based Fusion: Here, the LLM first generates multiple candidate outputs, which are then reranked or rescored based on their compatibility with the retrieved context, allowing for more controlled incorporation of external knowledge.
Reranking-based fusion strategies involve generating multiple candidate outputs and reranking them based on their compatibility with the retrieved context:
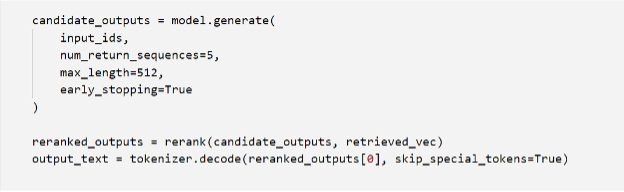
In this example, the rerank function would score each candidate output based on its compatibility with the retrieved context vectors retrieved_vec, potentially using techniques like cross-attention or learned scoring functions.
To better understand the inner workings of RAG systems, let's walk through an example that illustrates the key components and their interplay when processing a given prompt. Suppose we have a RAG system with a pre-trained language model and a retrieval component connected to a Wikipedia corpus. We'll use the following prompt as an example:

1. Query Encoding
The first step is to encode the input prompt into a high-dimensional vector representation using the pre-trained LLM's encoder:

Here, we use the pre-trained BERT model and tokenizer to encode the prompt into a vector representation query_vec.
2. Dense Vector Retrieval
Next, we use the encoded query vector to retrieve relevant passages from the Wikipedia corpus using dense vector search:

The retrieve function performs efficient nearest neighbor search in the vector space, returning the top-k most relevant passages from the indexed Wikipedia corpus.
3. Context Augmentation
The retrieved passages are then concatenated with the original prompt to form the augmented context for the LLM's decoder:

4. Language Generation
Finally, the LLM's decoder attends to the augmented context and generates the final output text, fusing the model's knowledge with the retrieved information:
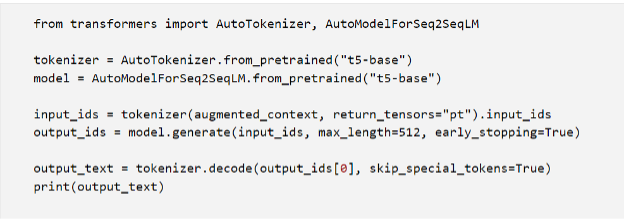
This code snippet uses the T5 sequence-to-sequence model for generation, taking the augmented context as input and generating the output text output_text. The generated output will likely be an informative response about the history of the Eiffel Tower's construction, incorporating both the LLM's knowledge and the relevant retrieved passages from Wikipedia.
As the scale and complexity of RAG systems grow, several challenges and considerations arise:
Efficient Indexing and Search: With massive external corpora, efficient indexing and retrieval techniques become crucial. Approaches like hierarchical clustering, approximate nearest neighbor search, and learned index structures can help scale billions or trillions of documents.
Retrieval Quality and Relevance: Improving the quality and relevance of retrieved information is an ongoing area of research, with approaches like dense-sparse hybrid retrieval, query reformulation, and iterative retrieval showing promising results.
Architectural Innovations: New model architectures and training strategies are being explored to better integrate retrieval and generation components, enabling more seamless fusion and knowledge grounding.
Factual Consistency and Hallucination Mitigation: As RAG systems become more capable, ensuring factual consistency and mitigating hallucinated or contradictory outputs remains a critical challenge, often addressed through techniques like consistency scoring, fact checking, and iterative refinement.
Ethical Considerations: As with any powerful AI system, RAG systems must be developed and deployed with careful consideration of ethical implications, such as potential biases in the retrieved data, privacy concerns, and responsible use of these technologies.
As language AI continues to advance, techniques like retrieval augmented generation that combine the strengths of large language models and external data access will likely play a pivotal role in building AI assistants with dynamic, ever-growing knowledge. While challenges remain in areas like efficient retrieval, knowledge grounding, and factual consistency, RAG represents a promising paradigm for keeping language models up-to-date and relevant in our rapidly evolving world.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-foundation-models-customize-rag.html
~ Author: Yasir UI Hadi

Our overburdened healthcare system leaves providers perpetually understaffed and overwhelmed — an increasingly dire situation both in India and globally. Doctors, nurses, and medical staff often work around the clock struggling to meet demand from ever-growing patient numbers [1]. While we cannot conjure more providers overnight or ignore those needing critical care, technology can help maximize efficiency for existing staff.
Minfy aims to streamline healthcare delivery to boost productivity. We offer a suite of AI-powered solutions for organizations of any size — from small clinics to major hospitals. These tools automate tedious tasks, freeing up precious staff hours for direct patient care.
Our flagship solution: an AI Discharge Report Generator creating concise, accurate summaries from complex medical records. What once took 20 gruelling minutes per patient [2] now requires just seconds, translating to over 30 rescued hours weekly for a typical hospital's discharge workflow.
The solution takes into consideration everything from admission and follow-ups to lab results and radiology, distilling volumes of data down to salient points. It then auto-populates a shareable summarized patient discharge report including treatment and diagnosis specifics, medications, post-discharge care plans and more — complete with custom formatting.
This game-changing efficiency allows doctors, nurses and technicians to redirect their focus toward broader care coordination, personalized treatment and critical decision making. With intuitive tools like discharge report automation, care providers can devote their precious skills more fully to patient interactions rather than paperwork.
AI handles the drudgery, while human insight guides compassion, Minfy’s vision of bionic journey. Combined properly, technology and medical expertise create a potent formula for Healthcare's immense challenges today and tomorrow. Our solutions ease overburdened systems to empower providers and enhance outcomes - one automated task at a time.
The heart of any solution lies in first deeply understanding the problem. Here, we saw providers burning out, overwhelmed creating discharge summaries - draining hours from pressing patient needs. Our solution uses AI to transform time-sinking paperwork into fast, personalized reports. Let’s dive deeper into;
The Problem: Creating discharge reports is extremely time-consuming for healthcare providers. Doctors spend about 30 hours every week putting these complex reports together by gathering lengthy records and test results. This manual and tiring process takes away precious time that doctors could instead directly spend caring for patients.
The Solution: We built an automated reporting system, powered by machine learning, that reduces reporting time from 20 minutes to less than 1 minute per patient. This frees up providers to deliver top-quality care vs. hunching over keyboards. Our 3-phase process transforms workflow efficiency:
1) Data Ingestion - Patient medical records across formats are pre-processed and fed into the system in a machine-readable structure optimized for AI.
2) Natural Language Generation - We fine-tuned a state-of-the-art large language model on real-world health data for accurate report drafting on custom HL7 FHIR compliant templates.
3) Automated Pipeline - Providers can now instantly generate summarized discharge reports with all salient details via our solution.
The core data powering our discharge report generator originates from hospitals' electronic health record (EHR) systems. This includes structured, unstructured and semi-structured data spanning admission assessments, follow-ups, progress notes, lab tests and radiology reports. Essentially, the complete picture of a patient's stay.
These records are securely transferred to Amazon S3 on a regular basis for processing. Text Documents, PDFs and scanned images first undergo optical character recognition (OCR) for text extraction. An ETL pipeline then handles validating, normalizing and cleaning all data to prepare it for analytics, while ensuring adherence to healthcare regulations around privacy, HIPAA Compliance.
Specifically, an automated workflow leverages Amazon Textract for OCR, Amazon Glue for crawling and cataloguing incremental data, and Glue ETL jobs for transformations. The outputs feed into a refined, analytics-ready dataset in an access-controlled S3 bucket after stripping personally identifiable information (PII) to respect privacy.
In the end, we gather disorderly patient data, wrangle it into a consistent structured format, and deliver cleansed, compliant and meaningful inputs to downstream AI systems - providing the foundation for fast discharge report generation.
We fine-tuned an open-source Large Language Model (LLM) to create discharge summaries from medical notes in HL7 FHIR format to enable interoperability between healthcare systems. Our goal is to automatically summarize relevant medical history, lab tests, procedures, follow-up instructions and medications from the unstructured doctors' notes.
We started with the Mistral 7B LLM as our base model due to its 7.3 billion parameter size and ability to generate high quality summaries while having lower latency for a model of this size. We fine-tuned this model on custom dataset to adapt it to the medical domain using Parameter-Efficient Fine-Tuning (PEFT) technique.

Total trainable parameters i.e. less than 1% of total parameters in Mistral 7B LLM
Finally, after carefully testing the model, it was deployed on a SageMaker endpoint to serve real-time inferences. The endpoint runs on a ml.g4dn.xlarge instance to provide a good throughput with sub-second latency for generating upto 1000 token summaries.
We implemented an automated pipeline to process medical reports and generate summarized discharge reports using our customized LLM. This pipeline utilizes several key AWS services:
An Amazon Lambda function orchestrates the workflow. This invokes a SageMaker endpoint hosting our custom LLM fine-tuned on medical text, passing the patient's reports data as input. The model analyses this text and returns a comprehensive HL7 FHIR compliant, summarized discharge report to the Lambda.
The Lambda then performs postprocessing. The summarized text is formatted into a shareable PDF and customized with hospital branding and relevant metadata. This polished report is uploaded to an encrypted Amazon S3 bucket for compliance and easy access. A unique, time-limited URL allows medical staff like physicians to securely view and download reports on-demand.
On the frontend, our intuitive web portal allows two key options: Healthcare staff can manually upload new documents or search historical records by patient ID to automatically process reports already within system. Users can preview reports before downloading locally for further review or signatures before being provided to patients.
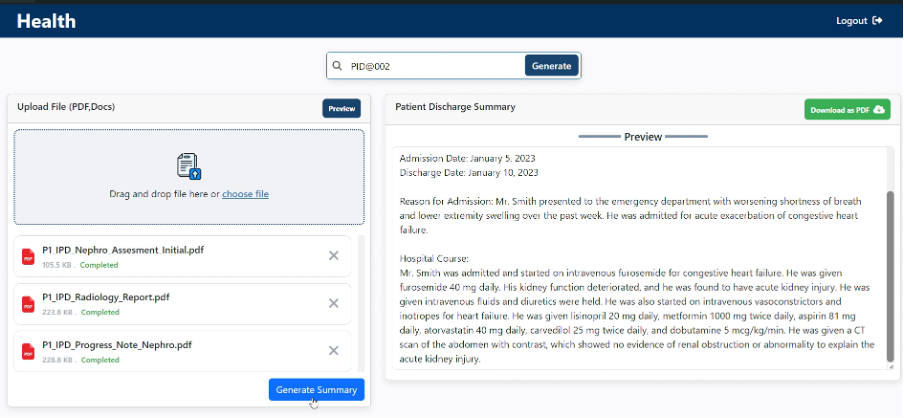
Web-Application UI to Manually Upload Documents
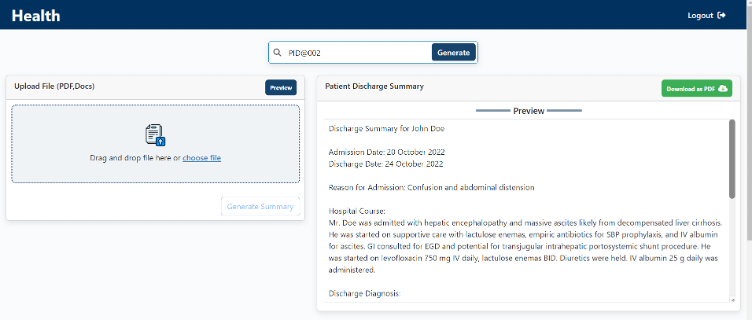
Web-Application UI to Search Historical Records by Patient ID

Downloaded Discharge Report View
Our automated discharge report solution showcases the immense potential of thoughtfully leveraging AI and cloud technology to enhance healthcare outcomes. By tackling a point of major inefficiency – the tedious task of creating discharge summaries – we have successfully demonstrated multiple high-impact capabilities with this solution:
1) Natural language generation fine-tuned on real-world data to auto-draft accurate, structured summaries in less than a minute rather than hours.
2) Seamless integration of leading services like Amazon Textract, SageMaker, Lambda and S3 to ingest, process, analyse and securely deliver data.
3) User-friendly web portal that allows providers to instantly search records and download compliant reports with custom formatting and branding.
4) Over 90% reduction in reporting time, freeing up providers to better utilize their specialized skills and human insight.
5) Template for expanding automation across other document-intensive hospital workflows.
The bottom line - our solution effectively combines the strengths of both powerful AI and dedicated medical staff to elevate care quality. We ease the data-driven work to reveal key insights faster, while leaving the compassionate critical thinking to professionals best qualified for it.
~ Author: Gaurav Lohkna
After the whole ChatGPT thing, we noticed a division amongst the users. Some believed that LLMs are good enough to take people’s job while others thought it has a long way to go. Well, I have learned that LLMs are a tool to perform tasks and the effectiveness, or their accuracy lies in the hands of the person asking them to perform these tasks. This is nothing but prompt engineering where a person effectively asks the model to execute certain tasks. The response of the model is directly affected by the prompts that it receives. An inaccurate or confused prompt will lead to an inaccurate response.
With these series of articles on prompt engineering, I am going to share some of the best practices for prompting that will help developers in quickly building software applications by leveraging the power of LLM APIs.
We will cover (with code) the following topics.
1. Prompting best practices for software development
2. Some common use cases such as
a. Summarizing
b. Inferring
c. Transforming
d. Expanding
3. Building a chatbot using an LLM
Note — these best practices are focused on Instruction tuned LLMs, such as GPT — 3.5 turbo
Before we start — This series of articles on prompt engineering is compiled from a recently launched course by Andrew Ng and Isa Fulford, you can find all the resources and the course here.
Let’s have a look at the setup.
Setup
Get your Open AI API key from here.

Let’s Begin!!
In the first part, let’s discuss the two basic principles, we will be using these throughout the series.
Principle 1. Write clear and specific instructions.
You should express what you want a model to do by providing instructions that are as clear and specific as you can possibly make them. This will guide the model towards the desired output and reduce the chance that you get irrelevant or incorrect responses. Don’t confuse writing a clear prompt with writing a short prompt, because in many cases, longer prompts actually provide more clarity and context for the model, which can actually lead to more detailed and relevant outputs.
Below are some of the tactics which will help you put this principle in action.
1. Use delimiters to clearly indicate distinct parts of the input. These could be triple backticks ```, triple quotes “””, XML tags <tag> </tags>, angle brackets < >, etc. anything that makes this clear to the model that this is a separate section. Using delimiters is also a helpful technique to try and avoid prompt injections. Prompt injection is, if a user is allowed to add some input into your prompt, they might give conflicting instructions to the model that might make it follow the user’s instructions rather than doing what you want it to do.

Output

2. Ask for a structured output.
To make parsing the model outputs easier, it can be helpful to ask for a structured output like HTML or JSON. This output can be directly read into dictionary or list using python.

Output

3. Ask the model to check whether conditions are satisfied. Check assumptions required to do the task.
In this example, we will ask the model to check if the text provided has a set of instructions or not. if it contains instructions then we are going to ask the model to rewrite these instructions in more readable fashion.
The first text contains instructions of making a tea.

Output

The second piece of text describes a sunny day and has no instructions.

Output

The model determined that there were no instructions in the text.
4. Few-shot prompting — Give successful examples of completing tasks then ask model to perform the task.
By this tactic, we’re telling the model that its task is to answer in a consistent style. The style used here is a conversation between a child and a grandparent where the child is asks a question and the grandparent answers with metaphors.
Next we feed this conversation to the model and see how the model replicates the style of the grandparent to answer the next question.

Output

These are some simple examples of how we can give the model a clear and specific instruction. Now, let’s move on to our second principle
Principle 2. Give the model time to think.
Generally, if a model is making reasoning errors by rushing to an incorrect conclusion, you should try reframing the query to request a chain or series of relevant reasoning before the model provides its final answer.
In other words, if you give a model a task that’s too complex for it to do in a short amount of time or in a small number of words, it may make up a guess which is likely to be incorrect.
The same thing would happen with a person too, if they are asked to solve a complex problem in a short amount of time, chances are, they will make mistakes.
To solve such issues and get the maximum outcome from a model’s intelligence, you can instruct the model to think longer about a problem which means it will spend more computational effort on the task to reach the right conclusion/answer.
So, let’s see some tactics and examples around our second principle.
1. Specify the steps required to complete a task.
In this example, we have used a text and we are going to specify multiple steps that the model will follow on the text.
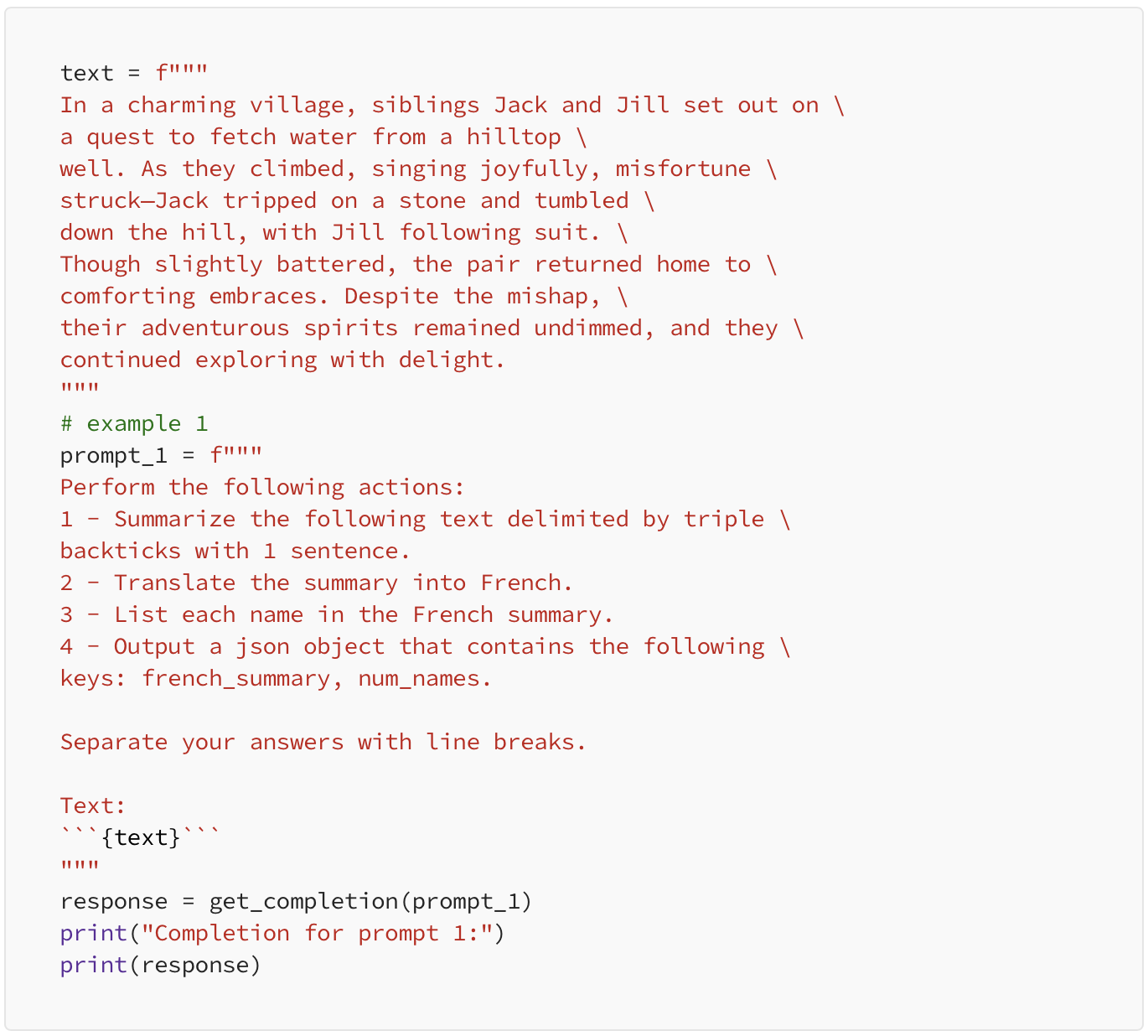
Output

Next, we may use earlier tactic and ask for the output to be in a specified format on the same text.

Output

2. Instruct the model to work out its own solution before rushing to a conclusion.
Let’s ask our model to evaluate a math solution, if it is correct or not.
The below prompt is a math question followed by a solution and the model is directly asked (in the beginning) to determine if the solution is correct or not.

Output

Please solve the problem and you’ll find that the student’s solution is actually not correct and to fix this, we will instruct the model to work out its own solution first and then compare the two results. Note that, when we are instructing the model, we are actually giving it the necessary time to think through the solution.
Below is the updated prompt.

Output

As we give the model enough time to think with specific instructions, the model successfully evaluates the solution and identifies the student’s answer as correct or incorrect.
Bonus principle — Model Limitations: Hallucinations Boie is a real company, the product name is not real.
While developing applications based on Large Language Models, one should always know the limitations of these models. If the model is being exposed to a vast amount of knowledge during its training process, it has not perfectly memorized the information it’s seen, and hence it doesn’t know the boundary of its knowledge very well. This means that the model might try to answer questions about obscure topics and can make things up that sound plausible but are not actually true and these fabricated ideas are called as Hallucinations.
Let’s see with the help of an example of a case where the model will hallucinate something. This is an example of where the model confabulates a description of a made-up product name from a real toothbrush company.
When we give the below prompt as input to our model, it gives us a realistic sounding description of a fictitious product.

Output

this is quite dangerous as the output generated looks very much realistic while it is completely false information.
So, make sure to use the techniques that we’ve gone through in this blog to try to avoid this when you’re building your own applications. This is a known weakness of LLMs and engineers are actively working on combating.
Reducing Hallucinations — First find relevant information, then answer the question based on the relevant information.
In the case that you want the model to generate answers based on a text, first ask the model to find any relevant quotes from the text, then ask it to use those quotes to answer questions and have a way to trace the answer back to the source document.
This tactic is often pretty helpful to reduce these hallucinations.
That’s it, we are done with the basic guidelines, principles and tactics for prompt engineering, in the next article, we will see some common use cases such as summarizing and inferring.
— Author: Rishi Khandelwal
As organizations generate massive amounts of data from various sources, the need for a scalable and cost-effective data storage and processing solution becomes critical. AWS (Amazon Web Services) offers a powerful platform for building a scalable data lake, enabling businesses to store, process, and analyze vast volumes of data efficiently. In this blog, we will dive deep into the process of constructing a robust and scalable data lake on AWS using various services like Amazon S3, AWS Glue, AWS Lambda, and Amazon Athena.
Defining a Data Lake
Before dive in, let's define what a data lake is. A data lake is a central repository that allows organizations to store and process vast amounts of structured and unstructured data at any scale. Unlike traditional databases or data warehouses, a data lake is flexible, capable of accommodating diverse data types, and can scale easily as data volumes increase.
In a data lake, there are entities known as data producers and data consumers. Data producers are responsible for gathering, processing, and storing data within their specific domain, which collectively makes up the content of the data lake. They have the option to share specific data assets with the data consumers of the data lake. Data consumers are users, applications, or systems that retrieve and analyse data from the data lake. They can be data analysts, data scientists, machine learning models, or other downstream processes. Tools like Amazon Athena and Amazon Redshift are used for querying and analysing data within the data lake.
Planning the Data Lake
A scalable data lake architecture establishes a robust framework for organizations to unlock the full potential of its data lake and seamlessly accommodate expanding data volumes. By ensuring uninterrupted data insights, regardless of scale, this architecture enhances your organization's competitiveness in the ever-evolving data landscape.
Efficiently managing data ingestion into data lakes is crucial for businesses as it can be time-consuming and resource-intensive. To optimize cost and extract maximum value from the data, many organizations opt for a one-time data ingestion approach, followed by multiple uses of the same data. To achieve scalability and cater to the increasing data production, sharing, and consumption, a well-thought-out data lake architecture becomes essential. This design ensures that as the data lake expands, it continues to deliver significant value to various business stakeholders.
Having a scalable data lake architecture establishes a strong framework for extracting value from the data lake and accommodating the influx of additional data. This uninterrupted scalability empowers the organization to continuously derive insights from the data without facing constraints, ensuring sustained competitiveness in the market.
Data Variety and Complexity:
As a data lake scales, the variety of data formats and structures also increases. This makes it challenging to maintain a unified data schema and to ensure compatibility across various data sources.
Data Ingestion Performance:
Scaling the data lake can lead to bottlenecks in data ingestion pipelines. High data volumes require efficient and parallelized data ingestion mechanisms.
Data Security and Access Control:
As the data lake grows, managing data access becomes crucial. Ensuring secure access to sensitive data while facilitating easy access for authorized users is a complex task.
Data Quality and Governance:
Maintaining data quality and enforcing governance policies become more difficult at scale. It's essential to have mechanisms to validate, cleanse, and transform data as it enters the lake.
Data Partitioning and Organization:
Proper data partitioning and organization are essential for efficient querying and processing. Without a thoughtful approach, query performance can degrade significantly.
Let's walk through the steps of building a scalable data lake on AWS, addressing the challenges mentioned above.
Amazon S3 Bucket Creation
• Log in to the AWS Management Console and navigate to the S3 service
• Create a new S3 bucket to store the raw data. Choose a unique bucket name, select the desired region, and configure the required settings (e.g., versioning, logging)
• Set up a folder structure within the bucket to organize data by source, date, or any relevant category. This structure helps in managing large volumes of data efficiently
AWS Glue for Data Catalog and ETL
AWS Glue allows us to discover, catalog, and transform data. It creates a metadata repository (Data Catalog) that helps in tracking data and schema changes. Additionally, Glue provides ETL capabilities to convert raw data into structured formats for querying.
• Go to the AWS Glue service in the AWS Management Console
• Create a new Glue Data Catalog database and relevant tables based on your data structure
• Define Glue ETL jobs using Python or Scala code to transform the data into a desired format.
• Here's an example of a Glue ETL job using Python:

Amazon Athena for Querying Data
Amazon Athena allows you to perform ad-hoc SQL queries on the data stored in S3 without the need for any data transformation upfront. It enables you to gain insights directly from the raw data.
• Go to the Amazon Athena service in the AWS Management Console
• Create a new database and corresponding tables in Athena using the Glue Data Catalog
• Write SQL queries to analyse and extract insights from the data. For example;

Data Ingestion into the Data Lake
Batch Data Ingestion
To ingest data into the Data Lake, you can use various methods, such as AWS DataSync, AWS Transfer Family, or AWS Glue DataBrew for data preparation. For batch data ingestion, AWS Glue ETL jobs can be scheduled to run periodically or triggered by specific events. Example of using AWS Glue DataBrew for batch data ingestion:

Real-time Data Ingestion
For real-time data ingestion, you can use services like Amazon Kinesis or AWS Lambda. Here's an example of using AWS Lambda to ingest real-time data into the Data Lake:

Defining Schema and Data Types
It is essential to define the schema and data types for the data stored in the Data Lake. This helps in ensuring consistent data and enables better query performance. You can use tools like AWS Glue Crawler to automatically infer the schema from the data, or you can provide a schema manually.
Data Cleaning and Standardization
Before performing analytics, it's crucial to clean and standardize the data to remove any inconsistencies and ensure data quality. You can achieve this through AWS Glue ETL jobs, using Spark transformations or Python functions.
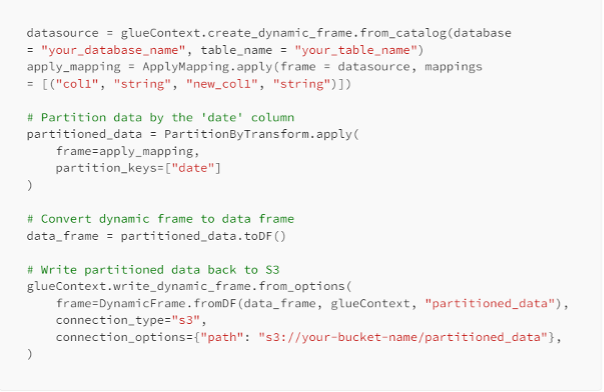
Partitioning Data for Performance
Partitioning data in the Data Lake helps improve query performance, especially for large datasets. It allows for faster data retrieval and reduces the data scan size. You can partition data based on relevant columns like date, region, or category.
Example of partitioning data in AWS Glue ETL job:
IAM Policies
AWS Identity and Access Management (IAM) policies help manage permissions and access to AWS resources. Ensure that you have defined appropriate IAM policies to control access to S3 buckets, Glue Data Catalog, and other services.
Example of an IAM policy for a user with access to specific S3 buckets:

S3 Bucket Policies
S3 bucket policies allow fine-grained control over access to the bucket and its objects. You can define policies to grant specific permissions to specific users or groups.
Example of an S3 bucket policy allowing read access to specific IAM users:

Amazon Redshift for Data Warehousing
For advanced analytics and data warehousing, you can integrate Amazon Redshift with your Data Lake. Amazon Redshift provides a high-performance data warehouse that allows you to run complex SQL queries and perform OLAP (Online Analytical Processing) tasks.

Amazon QuickSight for Data Visualization
Amazon QuickSight offers an easy-to-use business intelligence tool that enables you to create interactive dashboards and visualizations from data in your Data Lake.
Example of creating a QuickSight dashboard:
• Connect QuickSight to your Data Lake by creating a dataset
• Choose the relevant data tables from the Data Catalog.
Use the drag-and-drop interface to create visualizations and assemble them into a dashboard.
Data Governance and Compliance
Ensure that your Data Lake adheres to data governance and compliance standards, especially if you deal with sensitive or regulated data. Implement encryption mechanisms for data at rest and in transit, and apply access control to restrict data access to authorized users only.
Data Lake Monitoring and Scaling
Implement monitoring and logging mechanisms to track the performance, health, and usage of your Data Lake components. Use AWS CloudWatch for monitoring and set up alarms for critical metrics.
Additionally, design your Data Lake to scale effectively with growing data volumes. AWS services like S3 and Glue are designed to handle large-scale data, but it's essential to optimize your data storage and processing to ensure smooth performance.
Conclusion
Building a scalable data lake using AWS S3, Glue, and Lake Formation empowers organizations to handle vast amounts of data and extract valuable insights. With the steps and code examples provided in this blog post, you have the foundation to create a powerful data lake architecture that supports data-driven decision-making and analytics.
By following these best practices and utilizing AWS services, you can overcome the challenges of scaling a data lake and build a robust, scalable, and efficient data infrastructure that empowers your organization to extract valuable insights from your data.
Remember that data lake implementations can vary based on specific use cases and requirements. Be sure to continuously monitor and optimize your data lake architecture to make the most of AWS's powerful services.
— Yasir UI Hadi
References
https://docs.aws.amazon.com/prescriptive-guidance/latest/data-lake-for-growth-scale/welcome.html
https://aws.amazon.com/solutions/implementations/data-lake-solution/
In the world of healthcare data analytics, the challenge lies in making use of the vast amount of unstructured data that constitutes approximately 80% of all healthcare data [NCBI]. This unstructured data includes a variety of sources such as physician notes, prescription reports, lab reports, patient discharge summaries, and medical images, among others. While this data was never originally intended to be structured, the digital transformation revolution has motivated healthcare providers to harness its potential, leading to enhanced revenue streams, streamlined processes, and improved customer satisfaction [2].
However, the task of converting unstructured healthcare data into structured formats is no easy feat. Take, for instance, prescription reports or clinical notes – their complexity and heterogeneity make it difficult to fit them neatly into traditional databases and data tables like Excel or CSV files. The presence of inconsistent and cryptic medical terminologies further complicates the conversion process. Moreover, clinical jargon, acronyms, misspellings, and abbreviations add to the challenges faced during the conversion.
Despite these complexities, embracing the digital era revolution requires overcoming these hurdles. The abundance of unstructured medical data demands its effective utilization in analytics. By converting this data into structured or semi-structured formats, we can unlock its potential for advance analytics.
SOLUTION OVERVIEW:
The process of converting unstructured data into structured/semi-structured data involves several steps, including data extraction from documents, data cleaning and pre-processing, data mapping, data standardization, and data normalization. After these steps have been completed, the data is typically stored, analysed, and used to generate insights. This article delves into the process and its challenges, providing several examples to illustrate the application of these techniques on a sample dataset.
AWS offers an array of tools and services to assist healthcare providers in unlocking the full potential of their data. Our solution utilizes various AWS services like Amazon Textract to process a small sample of documents, extracting relevant data and converting it into FHIR resources within Amazon HealthLake to do analytics and ML modelling using Amazon SageMaker.
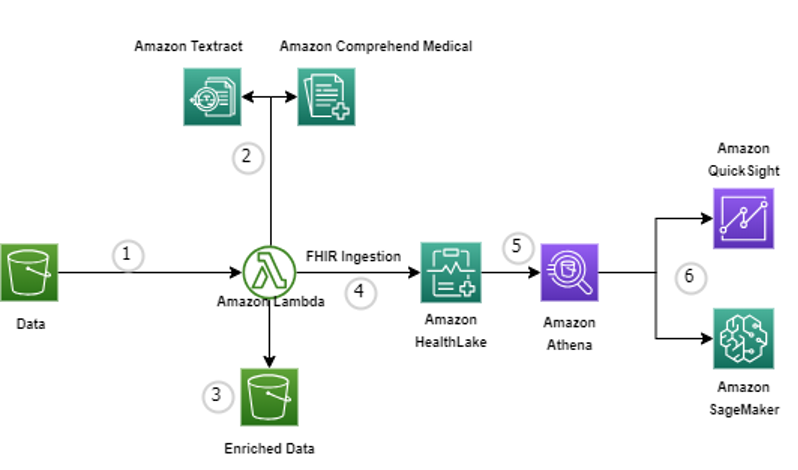
DATA EXTRACTION:
The foundation of utilizing unstructured healthcare data lies in the extraction of relevant information from various sources like images, PDFs, and scanned documents. This process involves leveraging the power of Optical Character Recognition (OCR) algorithms and tools, such as the widely available services like Amazon Textract. These algorithms and tools enable us to recognize, extract, and define output from the unstructured data, making it machine-readable and ready for further analysis
For example, I have taken a sample lab investigation report and ran Textract to get the extracted information in the CSV or Excel format.
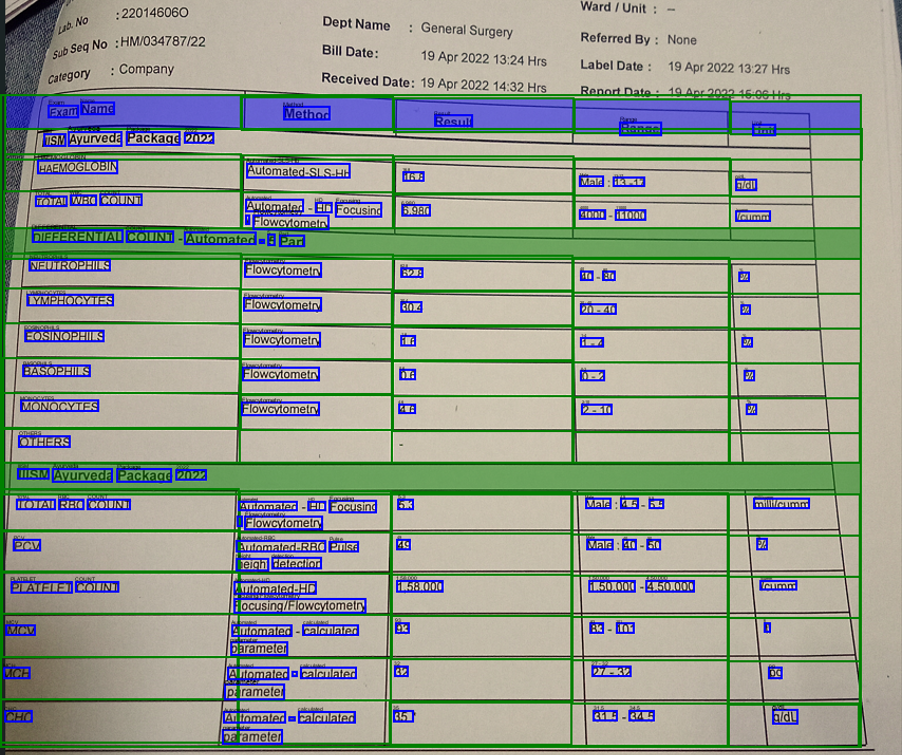
The corresponding output file of the unstructured document:
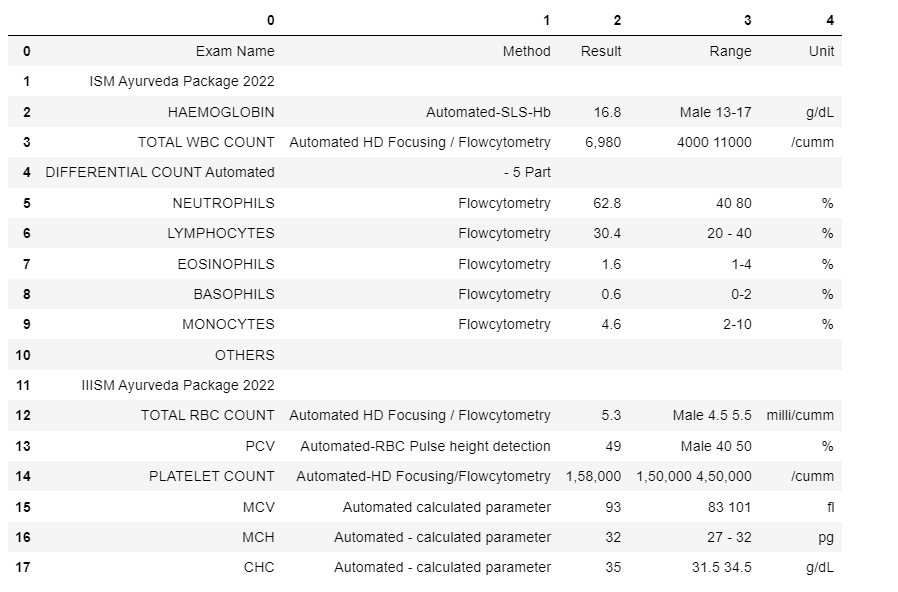
DATA PRE-PROCESSING
Once the data is extracted, the challenge lies in standardizing it to a uniform format for meaningful comparison and calculations. Natural Language Processing (NLP) techniques play a vital role in extracting valuable information from textual data. Services like Amazon Comprehend Medical can effectively handle entity recognition and identify standards within the data, making it easier for healthcare providers to interpret diagnoses, symptoms, treatments, and other crucial information.
For example, when we provide the Amazon Comprehend Medical some clinical information, it extracts the entities and tags them with various inbuilt attributes, as can be seen in the green-coloured highlights.
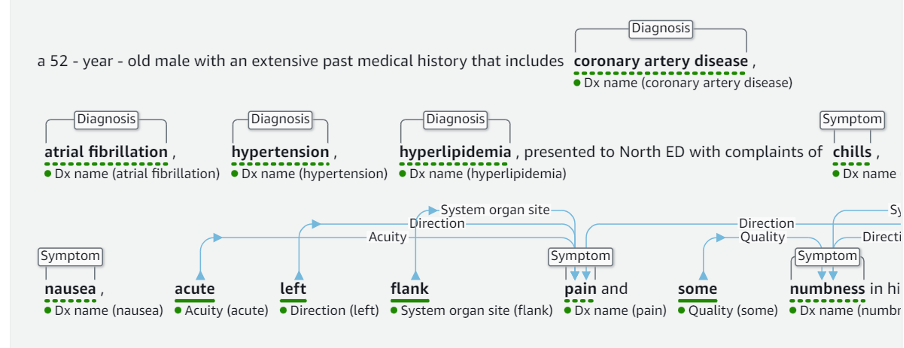
This process highlights certain things that a healthcare provider might need to look from the complete document and this recognition also provides us with a mapping of what were the diagnoses, symptoms, treatments and qualities etc.
DATA MAPPING, NORMALIZATION, & STANDARDIZATION
The extracted data is diverse and needs to be transformed to a common scale to facilitate meaningful comparison and calculations. Additionally, it is crucial to standardize terminology to ensure homogeneity of medical concepts across different datasets. Furthermore, data ontology plays a crucial role in establishing a common ground for understanding the data, thereby enhancing the accuracy and relevance of analyses by defining the relationships between different medical concepts.
In the healthcare domain, various coding systems have been utilized since the 1960s, including ICD, SNOMED CT, LOINC, and the most recent HL7 FHIR format. Mapping these unstructured data elements to these standards allows for a common understanding of medical concepts, which is crucial for data integration and interoperability.
We can convert and map the data into FHIR format for off-the-shelf analytics using Amazon HealthLake.
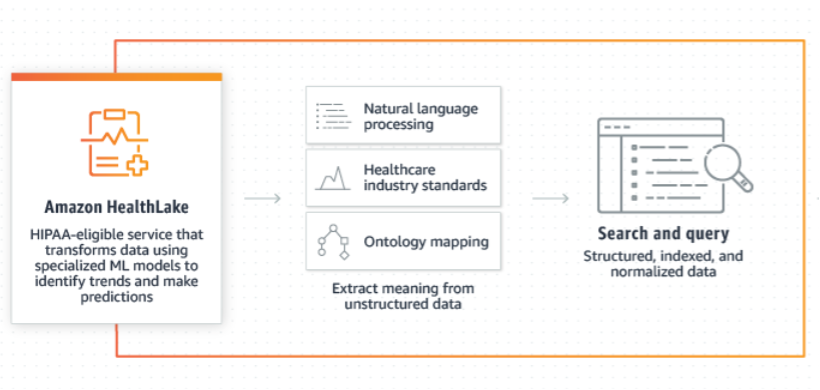
ANALYTICS:
We have successfully extracted, cleansed, and pre-processed the data stored in the Amazon HealthLake in the FHIR format. As a result, it is now structured and ready to be queried using Amazon Athena. We will proceed with conducting descriptive analysis of the patient data to gain insights into their current health status. We will use Amazon QuickSight to create dashboards that visualize the medical data.
For instance, we have patient lab investigation reports, and we have extracted the information along with unique identifiers such as UHID. We have performed the necessary preliminary steps to ensure that the data is usable.
Our descriptive analytics will involve creating a dashboard that displays vitals trends, health parameters abnormalities, a timeline view of medical events, the distribution of normality, and the classification of parameters based on abnormality. We will also include a health parameter value change indicator to compare the changes during a specific period.
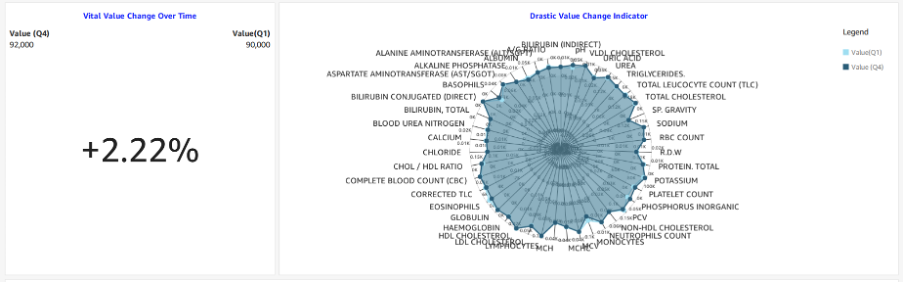

Once the data has been successfully extracted, cleaned, and pre-processed, advanced machine learning algorithms come into play. These powerful techniques enable healthcare professionals to determine patterns, trends. And correlations within the data, providing valuable insights into patient health and potential medical outcomes. By training predictive models on historical data, healthcare providers can forecast disease progression, identify high-risk patients, and even anticipate potential health complications, as I previously talked about in this article.
Additionally, predictive analytics empowers personalized care by tailoring treatment plans to individual patient needs, optimizing interventions, and ultimately leading to improved patient outcomes.
For example, in order to identify chronic kidney disease (CKD) at an early stage, it is important to monitor various factors such as the individual’s eGFR level, age, lifestyle, and other relevant indicators. Once this information has been gathered, machine-learning techniques can be utilized to aid in the detection process.
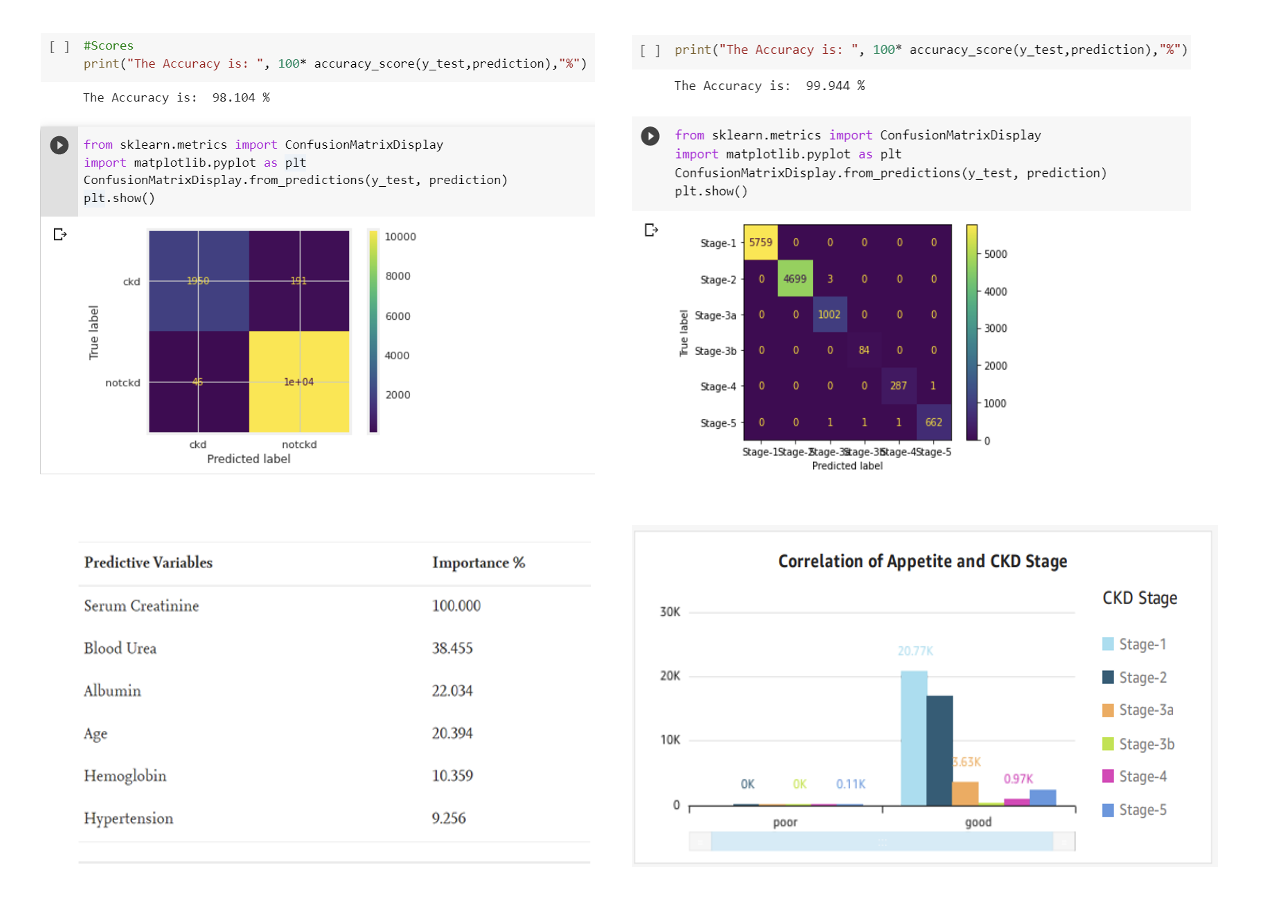
In the pursuit of leveraging unstructured healthcare data through advanced analytics, we face daunting challenges. However, by conquering complexity through data extraction, pre-processing, and standardization, an unknown world of insights awaits.
~ Author: Gaurav Lohkna
RESOURCES AND REFERENCES
Kong, H.-J. (2019). Managing Unstructured Big Data in Healthcare System. Healthcare Informatics Research, 25(1), https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6372467/
SyTrue (2015). Why Unstructured Data Holds the Key to Intelligent Healthcare Systems. [online] hitconsultant.net. Available at: https://hitconsultant.net/2015/03/31/tapping-unstructured-data-healthcares-biggest-hurdle-realized/
Image Source: https://treehousetechgroup.com/structured-data-vs-unstructured-data-whats-the-difference/
Mentioned Blog: https://www.minfytech.com/tackling-chronic-kidney-disease/

In the fast-paced landscape of healthcare, technology has emerged as a catalyst, propelling us into a new era of transformative change. It has revolutionized the way we improve efficiency and elevate patient outcomes, creating a ripple effect across the industry [1]. As I delved into the dynamic world of healthcare client partnerships, an intriguing trend caught my attention. A multitude of clients, driven by favorable government policies and a recognition of the immense potential, are venturing into the realm of innovation. With open arms, they are welcoming the convergence of Artificial Intelligence and Machine Learning (AIML) into their daily operations, forging a path toward remarkable breakthroughs.
This transformative shift is not a mere theory; it brings tangible advantages that industry experts have confirmed. In a report by McKinsey, it was revealed that organizations leveraging the power of data and embracing a data-driven approach are 23 times more likely to surpass their competitors in acquiring customers. Not only that, they are nine times more likely to retain customers and can achieve up to 19 times higher profitability. These statistics serve as an emphatic reminder of the undeniable edge gained by adopting data-driven strategies.
Recently, I had the privilege of collaborating with two visionary clients from the healthcare industry who were at the forefront of this transformative movement. Both organizations were fervently pursuing operational efficiency and harnessing the power of data analysis to unlock profound insights.
These clients, like many other healthcare organizations, found themselves immersed in an ocean of data, yearning for a solution that would enable them to derive comprehensive and refined treatment options, empowering their patients with optimal care. Enter Smart Health Reports — a combination of data analytics, artificial intelligence, and automation. This seminal approach empowers healthcare professionals with swift and thoughtful decision-making capabilities, propelling them toward delivering the highest standards of care. Join me in this article as we delve into the elaborateness of Smart Health Reports, exploring their potential, and unraveling the complications of implementing them within the dynamic healthcare ecosystem.
Smart Health Reports refer to a digital system that integrates data analytics, AI, and automation to generate comprehensive insights and information about individual patients or larger population health trends. These reports aim to streamline healthcare processes, improve efficiency, and enhance patient outcomes[2].
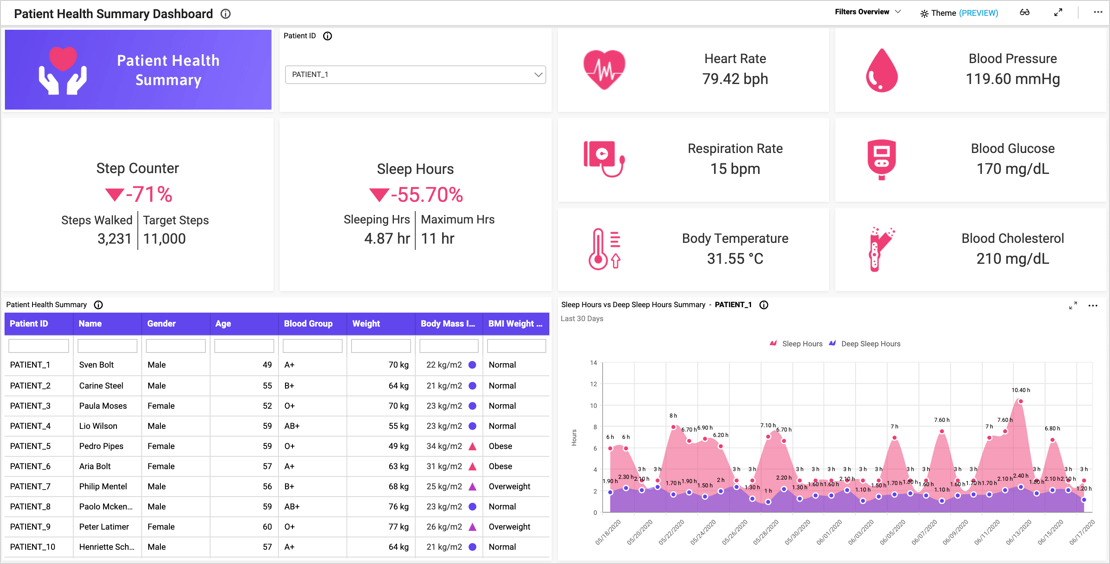
Smart Health Reports typically consist of the following components:
Data Collection: Smart Health Reports, which are positioned to impact the landscape of healthcare, depend upon data collection. These reports capitalize on the power of data analytics, artificial intelligence (AI), and automation. These reports provide a holistic view of an individual’s health or discover significant insights into broader health patterns by tapping into varied data sources such as electronic health records, medical devices, wearables, and patient-generated data.
Data Analytics: Beginning with the collecting of information from diverse sources, data analytics is a critical component of the healthcare system. Once collected, this data is subjected to advanced analytical techniques in order to reveal patterns, trends, and correlations. The resulting analysis provides healthcare practitioners with the knowledge they need to make informed decisions and develop personalized treatment plans. The healthcare industry is now able to optimize patient care and drive better health outcomes because of the power of data analytics[3].
Artificial Intelligence (AI): Artificial intelligence algorithms and machine learning models are integral components of Smart Health Reports. These technologies extract valuable insights from the data, enabling predictive analytics, risk assessment, and personalized healthcare recommendations. By utilizing AI, healthcare professionals can enhance their understanding of individual patients and proactively address potential health risks.
Automation: Automation plays a critical role in Smart Health Reports, providing a necessary value to their functionality. This feature allows for real-time reporting, automated alarms, and seamless connectivity with other healthcare systems, resulting in streamlined and efficient processes. Healthcare personnel can save time, reduce the risk of human mistakes, and assure the timely delivery of critical information by automating numerous operations. This feature emphasizes the transformative power of automation in improving healthcare practices.
The seamless integration of these components unlocks a powerful tool that provides healthcare professionals with timely and actionable information. This transformative capability goes beyond serving a specific audience, as Smart Health Reports cater to a diverse range of stakeholders, including doctors, nurses, researchers, policymakers, and even patients themselves.
Smart Health Reports bring a multitude of benefits that significantly enhance healthcare efficiency and patient outcomes. These reports empower healthcare professionals by providing valuable insights and streamlining decision-making processes through the utilization of data analytics, artificial intelligence, and automation. Let’s delve into the compelling features and capabilities of Smart Health Reports:
Real-time Data Collection and Analysis: Smart Health Reports employ advanced data collection methods, including integration with electronic health records (EHRs), medical devices, and wearable technology. This ensures the continuous capture of up-to-the-minute patient data, encompassing vital signs, laboratory results, and medical history. Through cutting-edge data analytics techniques, the reports process and analyze this information in near real-time, furnishing healthcare professionals with the latest actionable insights.
Predictive Analytics for Proactive Healthcare: Harnessing the power of AI and machine learning algorithms, Smart Health Reports have the ability to predict health outcomes and identify potential risks for individual patients. By analyzing historical patient data alongside relevant population health information, these reports detect patterns, trends, and risk factors. This proactive approach empowers healthcare professionals to intervene early, preventing or managing chronic conditions, reducing hospital readmissions, and ultimately enhancing overall patient well-being.
Customizable and User-friendly Interfaces: User experience lies at the heart of Smart Health Reports. These reports offer customizable interfaces, enabling healthcare professionals to personalize the data presentation to align with their preferences and workflow requirements. With intuitive and user-friendly dashboards, graphs, and visualizations, the reports facilitate swift interpretation and seamless navigation through complex datasets. This exceptional usability empowers efficient decision-making processes.
Decision Support Tools: Smart Health Reports often incorporate decision-support tools that provide evidence-based recommendations and guidelines to healthcare professionals. Drawing on a wealth of data and knowledge, these tools suggest appropriate diagnostic tests, treatment options, and medication recommendations tailored to patient-specific characteristics and best practices. This invaluable feature supports healthcare professionals in making informed decisions, reducing errors, and enhancing treatment outcomes.
Integration and Interoperability: Seamless integration with existing healthcare systems, such as EHRs, laboratory information systems, and telehealth platforms, is a hallmark of Smart Health Reports. This integration facilitates data and information exchange across diverse healthcare settings and providers, fostering care coordination and collaboration. Interoperability guarantees that healthcare professionals have access to a comprehensive patient overview, leading to well-informed decisions and improved continuity of care[4].
By embracing Smart Health Reports, healthcare professionals gain the tools and insights needed to revolutionize patient care. These reports optimize efficiency, enable proactive healthcare interventions, and facilitate seamless collaboration. Whether you are a healthcare provider, administrator, researcher, or patient, Smart Health Reports have the potential to drive positive change, improve health outcomes, and elevate the overall healthcare experience. Embrace this transformative technology and unlock a new era of healthcare excellence.
Implementing Smart Health Reports in healthcare settings comes with its own set of challenges and considerations. While these reports offer tremendous potential for improving healthcare efficiency, there are several factors that need to be addressed for successful integration within the healthcare ecosystem. Let’s explore some of the key implementation challenges and considerations:
Data Privacy and Security: In the realm of healthcare, safeguarding patient data holds the utmost significance. The integration of Smart Health Reports necessitates strict adherence to data privacy regulations, including the Health Insurance Portability and Accountability Act (HIPAA) in the United States and the proposed Digital Information Security in Healthcare Act (DISHA) in India. It is imperative for healthcare organizations to establish robust security measures to protect sensitive patient information from unauthorized access, breaches, and potential cyber threats. By prioritizing data security, healthcare entities can ensure the confidentiality and integrity of patient data, instilling trust and confidence in the healthcare ecosystem.
Interoperability and Integration: The integration of Smart Health Reports into existing healthcare systems can present complexities. Healthcare organizations frequently operate multiple systems, including electronic health records (EHRs), laboratory information systems, and imaging systems, which may not have seamless communication capabilities. Ensuring interoperability demands meticulous planning, collaborative efforts, and adherence to data standards. These measures are crucial to facilitate the smooth exchange of information across diverse platforms and providers, ultimately enhancing the overall functionality and effectiveness of healthcare systems.
Adoption and Training: The successful implementation of Smart Health Reports relies on healthcare professionals embracing and effectively utilizing these new technologies. Resistance to change and a lack of familiarity with the new system can hinder adoption. Healthcare organizations should provide comprehensive training programs to educate healthcare professionals on the benefits and functionalities of Smart Health Reports. User experience and user interface design should also be prioritized to ensure ease of use and minimize learning curves.
Cost and Infrastructure: Implementing Smart Health Reports requires healthcare organizations to carefully consider the financial aspects, as it may involve investments in software, hardware, and infrastructure upgrades. These organizations need to assess the potential return on investment (ROI) of such implementations. It is essential to evaluate the financial implications and weigh them against the expected benefits. Additionally, ensuring the availability of adequate IT infrastructure is crucial. This includes reliable networks to support seamless data exchange and secure data storage capabilities to handle the vast volumes of healthcare data generated by Smart Health Reports. Striking the right balance between financial considerations and the necessary technological infrastructure is key to successfully implementing these reports within healthcare organizations.
Ethical and Legal Considerations: The use of advanced technologies in healthcare raises ethical and legal considerations. Ethical dilemmas may arise when using AI algorithms for decision-making or when determining the scope of AI-driven automation in patient care. Healthcare organizations need to ensure that ethical frameworks and legal guidelines are established to govern the use of Smart Health Reports, maintaining a balance between technology-driven efficiency and patient-centric care [5].
Patient Engagement and Trust: Successfully implementing Smart Health Reports involves engaging and educating patients about the benefits and implications of these systems. Patients should be informed about how their data will be collected, stored, and used, ensuring transparency and obtaining their consent. Building trust with patients through effective communication can contribute to their acceptance and active participation in their own healthcare journey [6].
We are at a critical juncture in the dynamic world of smart healthcare. While fundamental principles and systems have been developed, the introduction of new technologies and problems opens up a wide range of opportunities for growth and advancement. It is now up to us to rise to the occasion and face these challenges with determination and resolution.
In this pursuit, collaboration becomes our greatest ally. We must join forces, bringing together healthcare organizations, technology providers, policymakers, and regulatory bodies, to confront the implementation challenges that lie ahead. By uniting our expertise, we have the power to unlock a future of enhanced efficiency, elevated patient care, and ultimately, better health outcomes within our healthcare systems.
The adoption of technological developments such as Smart Health Reports has moved from voluntary to mandatory in a fast-expanding healthcare market. It is the path that will allow us to provide efficient, patient-centered care, ultimately leading to better health outcomes for everyone. As a result, it is critical that we work together, push the boundaries, and truly embrace the transformative force of innovation as we journey towards a future where healthcare’s potential is limitless.
[1] https://www.sciencedirect.com/science/article/pii/S2414644719300508
Tian, S., Yang, W., Grange, J.M.L., Wang, P., Huang, W. and Ye, Z. (2019). Smart healthcare: making medical care more intelligent. Global Health Journal, [online] 3(3), pp.62–65. doi:https://doi.org/10.1016/j.glohj.2019.07.001.
[2] Doke, G. (2020). Enable Patients to Understand their Health with Medical Smart Reports. [online] CrelioHealth For Diagnostics. Available at: https://blog.creliohealth.com/enable-patients-to-understand-their-health-with-smart-reports/[Accessed 1 Jun. 2023].
[3] Cote, C. (2021). 3 Applications of Data Analytics in Healthcare. [online] Business Insights — Blog. Available at:https://online.hbs.edu/blog/post/data-analytics-in-healthcare.
[4] Cote, C. (2021). What Is Data Integrity and Why Does It Matter? [online] Business Insights — Blog. Available at:https://online.hbs.edu/blog/post/what-is-data-integrity.
[5] Farhud, D.D. and Zokaei, S. (2021). Ethical Issues of Artificial Intelligence in Medicine and Healthcare. Iranian Journal of Public Health, 50(11). doi:https://doi.org/10.18502/ijph.v50i11.7600.
[6] Mercer, S.W. (2004). The consultation and relational empathy (CARE) measure: development and preliminary validation and reliability of an empathy-based consultation process measure. Family Practice, 21(6), pp.699–705. doi:https://doi.org/10.1093/fampra/cmh621.
Generative AI, a form of artificial intelligence, has the ability to produce fresh content and concepts such as discussions, narratives, visuals, videos, and music. It relies on extensive pre-training of large models known as foundation models (FMs) using vast amounts of data.
AWS offers generative AI capabilities that empower you to revolutionize your applications, create entirely novel customer experiences, enhance productivity significantly, and drive transformative changes in your business. You have the flexibility to select from a variety of popular FMs or leverage AWS services that integrate generative AI seamlessly, all supported by cost-effective cloud infrastructure designed specifically for generative AI.
Unlike traditional ML models that require gathering labelled data, training multiple models, and deploying them for each specific task, foundation models offer a more efficient approach. With foundation models, there's no need to collect labelled data for every task or train numerous models. Instead, you can utilize the same pre-trained foundation model and adapt it to different tasks.
FM models possess an extensive array of parameters, enabling them to handle a diverse range of tasks and grasp intricate concepts. Moreover, their pre-training involves exposure to vast amounts of internet data, allowing them to acquire a profound understanding of numerous patterns and effectively apply their knowledge across various contexts.
Additionally, foundation models can be customized to perform domain-specific functions that provide unique advantages to your business. This customization process requires only a small portion of the data and computational resources typically needed to train a model from scratch. Customized FMs can make each customer's experience special by representing the company's personality, manner, and offerings in different fields like banking, travel, and healthcare.
Amazon CodeWhisperer is an AI coding companion that incorporates generative AI capabilities to enhance productivity. Furthermore, AWS offers sample solutions that combine their AI services with prominent Foundation Models to facilitate the deployment of popular generative AI use cases like call summarization and question answering.
Achieve optimal price-performance ratio for generative AI by utilizing infrastructure powered by AWS-designed ML chips and NVIDIA GPUs. Efficiently scale your infrastructure to train and deploy Foundation Models with hundreds of billions of parameters while maintaining cost-effectiveness.
AWS offers powerful instances, such as GPU-equipped EC2 instances, that can accelerate the training process. These instances are optimized for machine learning workloads and provide the necessary computational resources to train large language models efficiently.
Consider a variety of FMs offered by AI21 Labs, Anthropic, Stability AI, and Amazon to discover the most suitable model for your specific use case.
Easily tailor FMs for your business using a small set of labelled examples. Rest assured that your data stays secure and confidential as it is encrypted and never leaves your Amazon Virtual Private Cloud (VPC).
Effortlessly incorporate and implement FMs into your applications and workloads on AWS by leveraging the familiar controls and seamless integration with AWS's extensive range of capabilities and services, such as Amazon SageMaker, Jumpstart and Amazon S3.
Amazon Bedrock is a service that helps you access and use AI models created by top AI start-ups and Amazon. It provides an easy way to choose from a variety of models that are suitable for your specific needs. With Bedrock, you can quickly start using these models without worrying about managing servers or infrastructure.
You can also customize the models with your own data, and seamlessly integrate them into your applications using familiar AWS tools like Amazon SageMaker. Bedrock makes it easy to test different models and manage your AI models efficiently at a large scale.
We can select one FM from AI21 Labs, Anthropic, Stability AI, and Amazon to identify the most suitable FM for our specific needs.
Text Generation
Chatbot
Image Generation
Text summarization
Search
Personalization
CodeWhisperer leverages the power of state-of-the-art language models, such as GPT-3.5, to provide intelligent suggestions and solutions tailored to your coding needs. From syntax and code structure suggestions to algorithm optimizations and design patterns, CodeWhisperer analyses your code and offers valuable insights to help you write cleaner, more efficient code.
CodeWhisperer is an advanced AI model that has been extensively trained on an immense line of code, enabling it to swiftly provide code suggestions. These suggestions can range from small code snippets to complete functions, and they are generated in real time based on your comments and existing code. By leveraging CodeWhisperer, you can bypass time-consuming coding tasks and expedite the process of working with unfamiliar APIs.
It has the capability to identify and categorize code suggestions that closely resemble open-source training data. This feature enables the retrieval of the respective open-source project's repository URL and license information, facilitating convenient review and attribution.
Check your code for hidden security flaws that are difficult to detect. Receive suggestions on how to fix these issues right away. Follow the recommended security guidelines from organizations like OWASP and adhere to best practices for handling vulnerabilities, including those related to cryptographic libraries and other security measures.
Amazon has been focused on artificial intelligence (AI) and machine learning (ML) for more than 20 years. ML plays a significant role in many of the features and services that Amazon offers to its customers. There are thousands of engineers at Amazon who are dedicated to ML, and it is an important part of Amazon's history, values, and future. Amazon Titan models are created using Amazon's extensive experience in ML, with the goal of making ML accessible to everyone who wants to use it.
Amazon Titan FMs are highly capable models that have been pretrained on extensive datasets, enabling them to excel in various tasks. They can be utilized as they are or privately fine-tuned with your own data, eliminating the need to manually annotate significant amounts of data for a specific task.
Automate natural language tasks such as summarization and text generation
Titan Text is a generative large language model designed to perform tasks like summarization, text generation (such as creating blog posts), classification, open-ended question answering, and information extraction.
Enhance search accuracy and improve personalized recommendations
Titan Embeddings is an LLM that converts text inputs, such as words, phrases, or even longer sections of text, into numerical representations called embeddings. These embeddings capture the semantic meaning of the text. Although Titan Embeddings does not generate text itself, it offers value in applications such as personalization and search. By comparing embeddings, the model can provide responses that are more relevant and contextual compared to simple word matching.
Support responsible use of AI by reducing inappropriate or harmful content
Titan FMs are designed to identify and eliminate harmful content within data, decline inappropriate content within user input, and screen model outputs that may include inappropriate elements like hate speech, profanity, or violence.
Amazon SageMaker JumpStart provides pre-trained, open-source models for a wide range of problem types to help you get started with ML. You can incrementally train and tune these models before deployment. JumpStart also provides solution templates that set up infrastructure for common use cases, and executable example notebooks for ML with Amazon SageMaker.
Amazon SageMaker JumpStart is a valuable resource designed to speed up your machine learning endeavours. It serves as a hub where you can gain access to pre-trained models and foundational models available in the Foundations Model Hub.
These models enable you to carry out various tasks such as article summarization and image generation. The pre-trained models are highly adaptable to suit your specific use cases and can be seamlessly deployed in production using either the user interface or the software development kit (SDK).
It's worth noting that none of your data is utilized in the training of the underlying models. Your data is securely encrypted and remains within the virtual private cloud (VPC), ensuring utmost privacy and confidentiality.
Jumpstart GPT-2 model, facilitates the generation of text resembling human language by leveraging a given prompt. This transformative model proves valuable in automating the writing process and generating fresh sentences. Its applications range from creating content for blogs and social media posts to crafting books.
Belonging to the Generative Pre-Trained Transformer series, GPT-2 served as the precursor to GPT-3. However, the OpenAI ChatGPT application currently relies on the GPT-3 model as its foundation.
AWS Trainium is a specialized machine learning (ML) accelerator developed by AWS for training deep learning models with over 100 billion parameters. Each Amazon Elastic Compute Cloud (EC2) Trn1 instance is equipped with up to 16 AWS Trainium accelerators, providing a cost-effective and high-performance solution for cloud-based deep learning training.
While the adoption of deep learning is growing rapidly, many development teams face budget constraints that limit the extent and frequency of training required to enhance their models and applications. EC2 Trn1 instances powered by Trainium address this challenge by enabling faster training times and delivering up to 50% cost savings compared to similar Amazon EC2 instances.
Trainium has been specifically designed for training natural language processing, computer vision, and recommender models that find applications in a wide range of areas, including text summarization, code generation, question answering, image and video generation, recommendation systems, and fraud detection.
Currently, a significant amount of time and resources are dedicated to training FMs (machine learning models) because most customers are just beginning to implement them in practical applications
However, as FMs become widely deployed in the future, the majority of expenses will be associated with running the models and performing inferences. Unlike training, which occurs periodically, a production system continuously generates predictions or inferences, potentially reaching millions per hour
These inferences must be processed in real-time, necessitating low-latency and high-throughput networking capabilities. A prime example of this is Alexa, which receives millions of requests every minute and contributes to 40% of total compute costs
Amazon recognized the significant impact that running inferences would have on the costs of machine learning in the future. As a result, they made it a priority to invest in chips optimized for inference several years ago
In 2018, they introduced Inferentia, the first specialized chip designed specifically for inference tasks. Inferentia has been instrumental in enabling Amazon to perform trillions of inferences each year, resulting in substantial savings of over a hundred million dollars in capital expenses for companies like Amazon
The achievements that have been witnessed so far are remarkable, and foresee numerous opportunities to continue our innovation efforts, particularly as workloads become larger and more complex with the integration of generative AI into various applications
AWS is currently engaged in the exploration of methods to empower customers in utilizing the LLM’s effectively, enabling them to offer distinctive and exceptional experiences to their own customers while keeping the required effort to a minimum. The goal is to establish a system where customers can make use of foundational models created by AWS partners like Anthropic, Stability AI, and Hugging Face, thereby delivering value to the market.
AWS aims to provide customers with the tools and support necessary to create personalized Generative AI solutions tailored to their individual needs and preferences.
References
https://aws.amazon.com/generative-ai/
https://aws.amazon.com/bedrock/
https://aws.amazon.com/machine-learning/trainium/
https://aws.amazon.com/blogs/machine-learning/deploy-generative-ai-models-from-amazon-sagemaker-jumpstart-using-the-aws-cdk/
https://aws.amazon.com/blogs/machine-learning/build-a-serverless-meeting-summarization-backend-with-large-language-models-on-amazon-sagemaker-jumpstart/
Main cost for any distribution utility is the cost of power (80% of the total cost*), since power needs to be managed in real time, means utility need to consume all that they have purchased. In case of deviation which is either in form of a surplus or deficit, the utility has an option of buying or selling in the market- either day ahead or during the day in the real time market
Also, the grid stability requires that states schedule only the quantum they can consume else there is risk of grid failure and to ensure grid stability the regional grid imposes a deviation settlement penalty on the concerned state.
In case of failure to accurately predict the demand for next day or for next few hours there is a significant commercial impact on the states, which is estimated to be in the range of 0.5-2% *of their power purchase cost. Power purchase cost varies from state to state but can be estimated to be in the range of INR 100 billion to INR 300 billion* for major states in the country. The uncertainty is going to be higher as the share of renewable energy in the energy mix increase, due to the intermittent nature of its supply. The generation of the RE energy also needs to be forecasted to accurately predict the supply.
Time series forecasting means to predict the future value of an item over a period. With Minfy’s AI capabilities, a machine learning solution was proposed, by leveraging the power of AWS’s AI services like Amazon SageMaker and Amazon Forecast.
Minfy demonstrated with a proof of concept, that using historical electricity demand data, we can build, train and deploy a machine learning model to produce forecast with accurate results.
The historical demand data is first uploaded to a S3 bucket. Using a Jupyter notebook instance of Amazon SageMaker, the timeseries data which includes four different timeseries, is then prepared for training different machine learning models.

Figure 1 Historical Demand Data
The data pre-processing includes the following steps
1. Managing outliers – Outliers are the data points that significantly differs from the patterns and trends of the other values in the timeseries. It can happen due to reasons such as equipment failure, power failure due to electrical faults, human error, etc. these outliers can hinder the learning process of our machine learning models so it is needed to change the values of these data points. Machine learning techniques such as forward filling, backward filling, polynomial interpolation, etc are used to change the value of these outliers
2. Data Analysis – after cleaning the dataset, it is analysed to gain insights about the seasonality, trends and noise in the data. This analysis is crucial to create additional features that will help the machine learning models to learn better
3. Feature creation – with the help of the analysis, new additional features are created and are used as “related time series” by AWS forecasting models.
4. Transforming the dataset – Different machine learning models require data to be in different formats such as csv, jsonlines, etc. In this last step, the dataset is transformed and partitioned into training data and testing data and is ready to be fed to different models
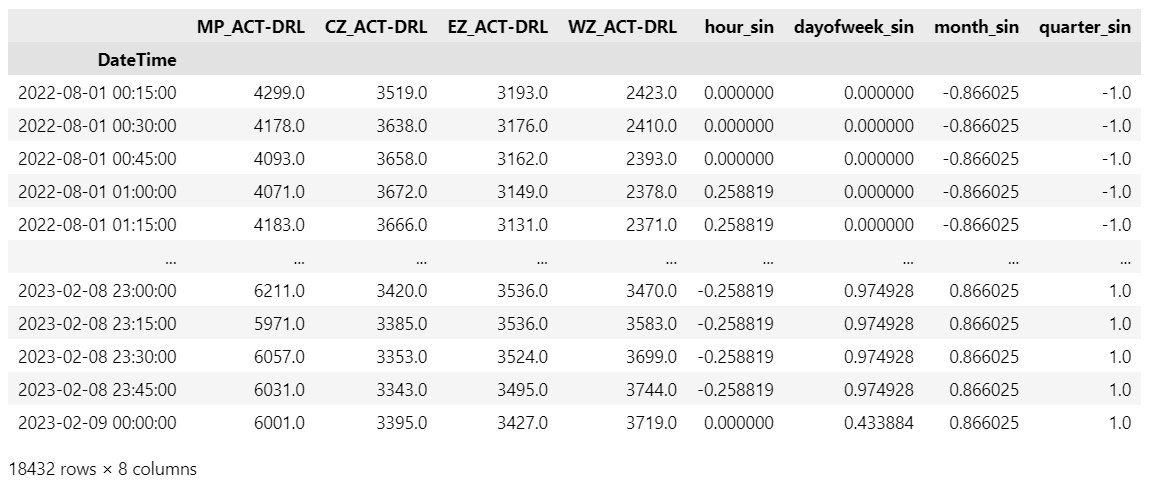
Figure 2 Training Data
We train multiple machine learning models such as Amazon Forecast – AutoML, DeepAR, etc. and test them over a period (rolling window). The performances of these models are compared on multiple parameters such as training time, inferencing time, and the total cost of training. Lastly, as model’s accuracy decreases with time due to change in demand patterns, it is required to train the models on the most recent data points.
An inferencing pipeline is developed for our 1-month trial period. During this 1 month, demand data of previous day was uploaded to s3, it was then processed using the same methodology as above, and then used as “context data” to forecast demand for the next day. As we move forward, the forecasted values are compared with the true values and the results are stored.
With Minfy’s forecasting solution, PTC saw results of 98% accurate (0.02 MAPE) for intraday forecasting and over 90% (0.1 MAPE) for day-ahead forecasting. The training time for the model was reduced from 4 hours to just 40 minutes. The inferencing time was reduced to a few seconds.
Deviation settlement penalty worth INR 1-6 billion* can be saved, as the forecasted values are within the permissible range (5%) from true values. Also, With AWS’s infrastructure, the solution can be deployed within weeks compared to on-prem setup, which would take months.
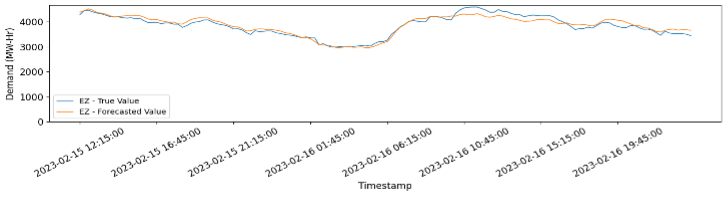
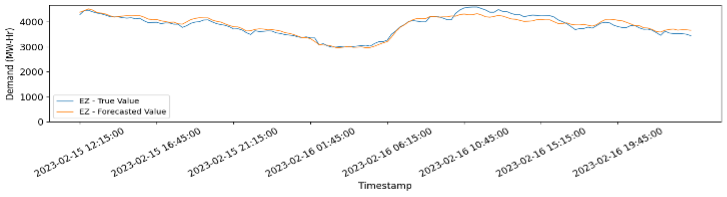
Figure 3 Comparison of True and Forecasted Values for East zone and Central Zone, starting from 15th Feb, 12:15:00 till 18th Feb 00:00

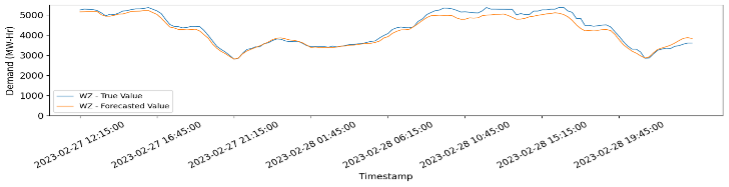
Figure 4 Comparison of True and Forecasted values for West zone and MP, starting from 27th Feb, 12:15:00 till 1st March 00:00.
* Data source – PTC India
PTC is a pioneer in starting a power market in India and undertakes trading activities that include long-term trading of power generated from large power projects, as well as short-term trading arising from supply-and-demand mismatches that inevitably arise in various regions of the country. Since July 2001, when it started trading power on a sustainable basis, PTC has provided optimal value to both buyers and sellers while ensuring optimum usage of resources. PTC has grown from strength to strength, surpassing expectations of growth and has evolved into a Rs.3,496.60 Crore as of March 2020, with a client base that covers all the state utilities of the country, as well as some power utilities in the neighboring countries. https://www.ptcindia.com/
— Author:

Arun Kumar (Head of Technology & Short-Term Power Market, PTC)
Arun Kumar is head of technology and short-term power market at PTC. Arun has over 25 years of experience in the power sector as a corporate leader, equity analyst, and management consultant. Arun previously set up a full-fledged forecasting team, providing demand and renewable-generation forecasting solutions to RLDC, SLDC, DISCOMs, and RE generators. The solution was using a conventional SQL database where the data and weather science team created forecasting algorithms and trained models for generating the outputs. He used the AWS tool for the first time and found the experience very rewarding and cost effective.

Jigar Jain (Project Manager, PTC)
Jigar Jain is project manager at PTC. Jigar is a cloud practitioner and enthusiast. Since 2021, Jigar has been responsible for making major decisions while moving to the cloud and cloud-native architecture at PTC India. Currently, Jigar is actively working on blockchain technologies and sustainability on the cloud.

Rishi Khandelwal (Deeptech Associate Consultant, Minfy)
Rishi Khandelwal is Data scientist at Minfy. He aims to solve challenges in the Energy and Resources Industry. After completing his Masters in AI and Entrepreneurship in 2022, Rishi joined Minfy to help companies leverage the power of data to solve business challenges.
What is predictive maintenance and how does it work?
Artificial intelligence (AI) is transforming the energy and resources industry in many ways, including predictive maintenance. AI powered predictive maintenance is a data-driven approach that uses machine learning (ML) algorithms to address some of the crucial challenges related to machine maintenance.
The energy industry is heavily reliant on machinery and equipment. These assets are critical for operations and require ongoing maintenance to operate effectively. Traditional maintenance approaches, such as reactive or scheduled maintenance, can be costly and inefficient.
Reactive maintenance involves fixing equipment after a breakdown has occurred, leading to costly downtime and repairs whereas scheduled maintenance involves conducting maintenance at set intervals, regardless of the condition of the equipment leading to unnecessary maintenance and downtime.
Both these methods of performing maintenance are not smart and leads to wastage of resources.
Predictive maintenance, on the other hand, uses data to predict when equipment is likely to fail and schedule maintenance accordingly. This approach can help companies reduce downtime, extend the life of equipment, and increase safety. AI and ML algorithms are used to analyse data from sensors and other sources to identify patterns and anomalies. Predictive ML models are then developed to predict when maintenance will be required.
Now, let’s look at what can be achieved using AI powered predictive maintenance solutions.
First, we need to understand what type of data is involved in the process. Generally, there are two types of data involved in building such systems.
1. Images
2. Sensors’ reading – analogue signals and numbers
This data is used to answer three types of questions which leads to three different use cases.
1. Is the machine behaving abnormally? – Anomaly detection
2. Is there a fault in my system? And what is the root cause? – fault classification or root cause isolation
3. When is the machine likely to encounter a fault condition? – Remaining useful life estimation.
Once we have clarity on what we want to achieve using predictive maintenance solution, it is time to move onto the next steps of building the solution.
Developing the solution involves multiple steps described below.
1. Data acquisition – Collecting relevant data to solve a problem is the base of any machine learning solution. Data is collected either from the sensors attached to the equipment or from images captured during operation.
2. Data analysis – Once the data is stored, it is analysed using signal processing techniques (extracting, manipulating, and storing information embedded in complex signals and images) and desired features are extracted from it.
3. Modelling – Once the data type and the problem statement is clear, we can make a choice and select the right type of ML algorithm. For example, while working with image data, we can use deep neural network-based architecture such as Convolutional Neural Network (CNN) to classify if the equipment is damaged or not. Once the training process is complete, next we set up an inferencing pipeline which is used to query from the model.
Generally we use CNNs with image input. It’s not clear what you mean by automating feature selection from image data. For fault detection do we need something like semantic segmentation? If yes you need to explain that.
Let’s talk about key considerations with building AI powered predictive maintenance solution -
• Data collection – We need enough data to cover all the use cases we want our solution to deliver. Data corresponding to fault or failure conditions is usually difficult to obtain as the incidents of failures are relatively few. One way to solve this problem is by simulating scenarios to capture fake failure . Another way is using existing failure data to create more failure data using machine learning.
• Data engineering and analysis – Managing large amounts of data cost efficiently is a challenging task. Machine sensors might produce data in GBs every day, and to process, store and analyse this data requires robust data pipelines.
• Feature extraction – The data which will be used for training the ML models should contain maximum information and minimum noise. If the features are not relevant to the problem, resources will get wasted in training models with such data. So, subject matter expertise is important to extract as much information as possible while reducing the size of the data set.
In the energy and resources industry, predictive maintenance can be used for a wide range of equipment, including turbines, compressors, pumps, and generators. Let’s have a look at some of these examples.
• Predictive maintenance to monitor the condition of wind turbines – Data from sensors on the turbines is used to monitor parameters such as temperature, vibration, and oil levels. ML models can then analyse this data to predict when maintenance will be required. This can help companies schedule maintenance during periods of low wind activity, reducing downtime and increasing energy production.
• Predictive maintenance to monitor the condition of pipelines and other infrastructure – Data from sensors placed along pipelines is used to monitor parameters such as pressure, temperature, and flow rate. ML models can then analyze this data to predict when maintenance will be required. This can help companies identify potential leaks or failures before they occur, reducing the risk of accidents and downtime.
Here’s an example of how to leverage AI to predict Remaining Useful Life (RUL) for an equipment.
We can build, deploy and scale AI powered solutions on AWS. Below is one such solution for predicting remaining useful life of an equipment.
The example uses Amazon SageMaker to train a deep learning ML model with the MXNet deep learning framework. The model is a stacked bidirectional LSTM neural network that can learn from sequential or time series data. The model is robust to the input dataset and does not expect the sensor readings to be smoothed, as the model has 1D convolutional layers with trainable parameter that can smooth and perform feature transformation of the time series. The deep learning model is trained so that it learns to predict the remaining useful life (RUL) for each sensor
The historical sensor data is stored in S3 bucket and from here it will be used to train the deep learning model
Training
• Once the training data is stored in a S3 Bucket, model training code is written in a Jupyter notebook running on an Amazon Sagemaker notebook instance.
• The MXNet model is trained and the model artifacts are stored in a S3 bucket.
Inferencing
• AWS Lambda function is included to perform batch inference on new data that comes from sensors and is stored in an Amazon S3 bucket
• The Lambda function can be invoked by an AWS CloudWatch Event or with a S3 put event notification so that it runs on a schedule or as soon as new sensor readings are stored in S3
• When invoked, the Lambda function creates a Sagemaker Batch Transform job, which uses the Sagemaker Model that was saved during training, to obtain model predictions for the new sensor data
• The results of the batch transform job are stored back in S3, and can be fed into a dashboard or visualization module for monitoring
To conclude, if there is enough sensor data available, we can harness its power and shift from a reactive/scheduled method to AI powered predicitive maintenance. Amazon Web Services accelerates the process of building such solutions. This will help companies save on their operations by cutting down on their maintenance cost and improving overall reliability of the system.
— Author: Rishi Khandelwal
This website stores cookie on your computer. These cookies are used to collect information about how you interact with our website and allow us to remember you. We use this information in order to improve and customize your browsing experience and for analytics and metrics about our visitors both on this website and other media. To find out more about the cookies we use, see our Privacy Policy. If you decline, your information won’t be tracked when you visit this website. A single cookie will be used in your browser to remember your preference not to be tracked.