 Go to Swayam
Go to Swayam- Home
- About
- Consulting
- Services
- Minfy Labs
- Industries
- Resonances
- Careers
- Contact
After the whole ChatGPT thing, we noticed a division amongst the users. Some believed that LLMs are good enough to take people’s job while others thought it has a long way to go. Well, I have learned that LLMs are a tool to perform tasks and the effectiveness, or their accuracy lies in the hands of the person asking them to perform these tasks. This is nothing but prompt engineering where a person effectively asks the model to execute certain tasks. The response of the model is directly affected by the prompts that it receives. An inaccurate or confused prompt will lead to an inaccurate response.
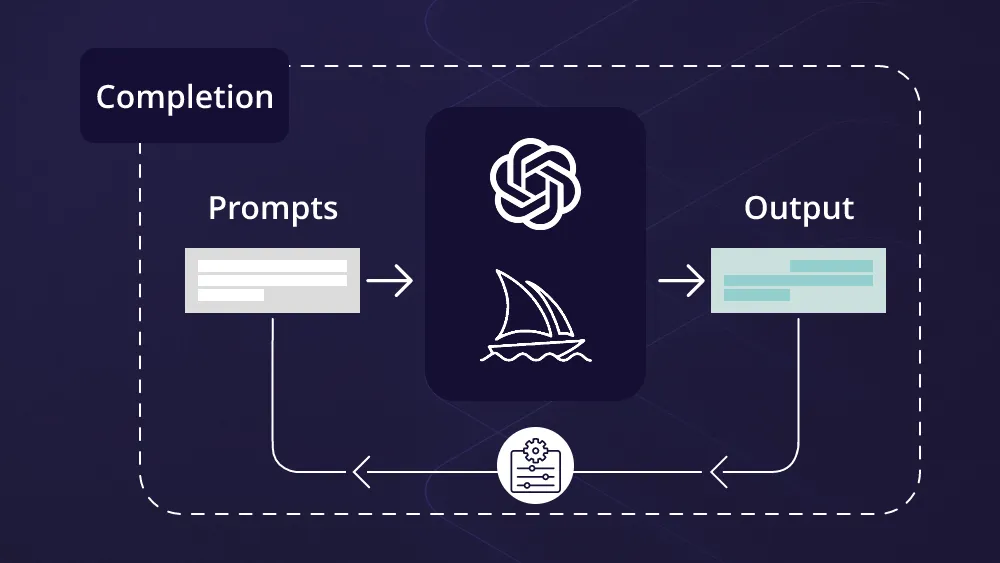
With these series of articles on prompt engineering, I am going to share some of the best practices for prompting that will help developers in quickly building software applications by leveraging the power of LLM APIs.
We will cover (with code) the following topics.
1. Prompting best practices for software development
2. Some common use cases such as
a. Summarizing
b. Inferring
c. Transforming
d. Expanding
3. Building a chatbot using an LLM
Note — these best practices are focused on Instruction tuned LLMs, such as GPT — 3.5 turbo
Before we start — This series of articles on prompt engineering is compiled from a recently launched course by Andrew Ng and Isa Fulford, you can find all the resources and the course here.
Let’s have a look at the setup.
Setup
Get your Open AI API key from here.

Let’s Begin!!
In the first part, let’s discuss the two basic principles, we will be using these throughout the series.
Principle 1. Write clear and specific instructions.
You should express what you want a model to do by providing instructions that are as clear and specific as you can possibly make them. This will guide the model towards the desired output and reduce the chance that you get irrelevant or incorrect responses. Don’t confuse writing a clear prompt with writing a short prompt, because in many cases, longer prompts actually provide more clarity and context for the model, which can actually lead to more detailed and relevant outputs.
Below are some of the tactics which will help you put this principle in action.
1. Use delimiters to clearly indicate distinct parts of the input. These could be triple backticks ```, triple quotes “””, XML tags <tag> </tags>, angle brackets < >, etc. anything that makes this clear to the model that this is a separate section. Using delimiters is also a helpful technique to try and avoid prompt injections. Prompt injection is, if a user is allowed to add some input into your prompt, they might give conflicting instructions to the model that might make it follow the user’s instructions rather than doing what you want it to do.

Output

2. Ask for a structured output.
To make parsing the model outputs easier, it can be helpful to ask for a structured output like HTML or JSON. This output can be directly read into dictionary or list using python.

Output

3. Ask the model to check whether conditions are satisfied. Check assumptions required to do the task.
In this example, we will ask the model to check if the text provided has a set of instructions or not. if it contains instructions then we are going to ask the model to rewrite these instructions in more readable fashion.
The first text contains instructions of making a tea.

Output

The second piece of text describes a sunny day and has no instructions.

Output

The model determined that there were no instructions in the text.
4. Few-shot prompting — Give successful examples of completing tasks then ask model to perform the task.
By this tactic, we’re telling the model that its task is to answer in a consistent style. The style used here is a conversation between a child and a grandparent where the child is asks a question and the grandparent answers with metaphors.
Next we feed this conversation to the model and see how the model replicates the style of the grandparent to answer the next question.

Output

These are some simple examples of how we can give the model a clear and specific instruction. Now, let’s move on to our second principle
Principle 2. Give the model time to think.
Generally, if a model is making reasoning errors by rushing to an incorrect conclusion, you should try reframing the query to request a chain or series of relevant reasoning before the model provides its final answer.
In other words, if you give a model a task that’s too complex for it to do in a short amount of time or in a small number of words, it may make up a guess which is likely to be incorrect.
The same thing would happen with a person too, if they are asked to solve a complex problem in a short amount of time, chances are, they will make mistakes.
To solve such issues and get the maximum outcome from a model’s intelligence, you can instruct the model to think longer about a problem which means it will spend more computational effort on the task to reach the right conclusion/answer.
So, let’s see some tactics and examples around our second principle.
1. Specify the steps required to complete a task.
In this example, we have used a text and we are going to specify multiple steps that the model will follow on the text.
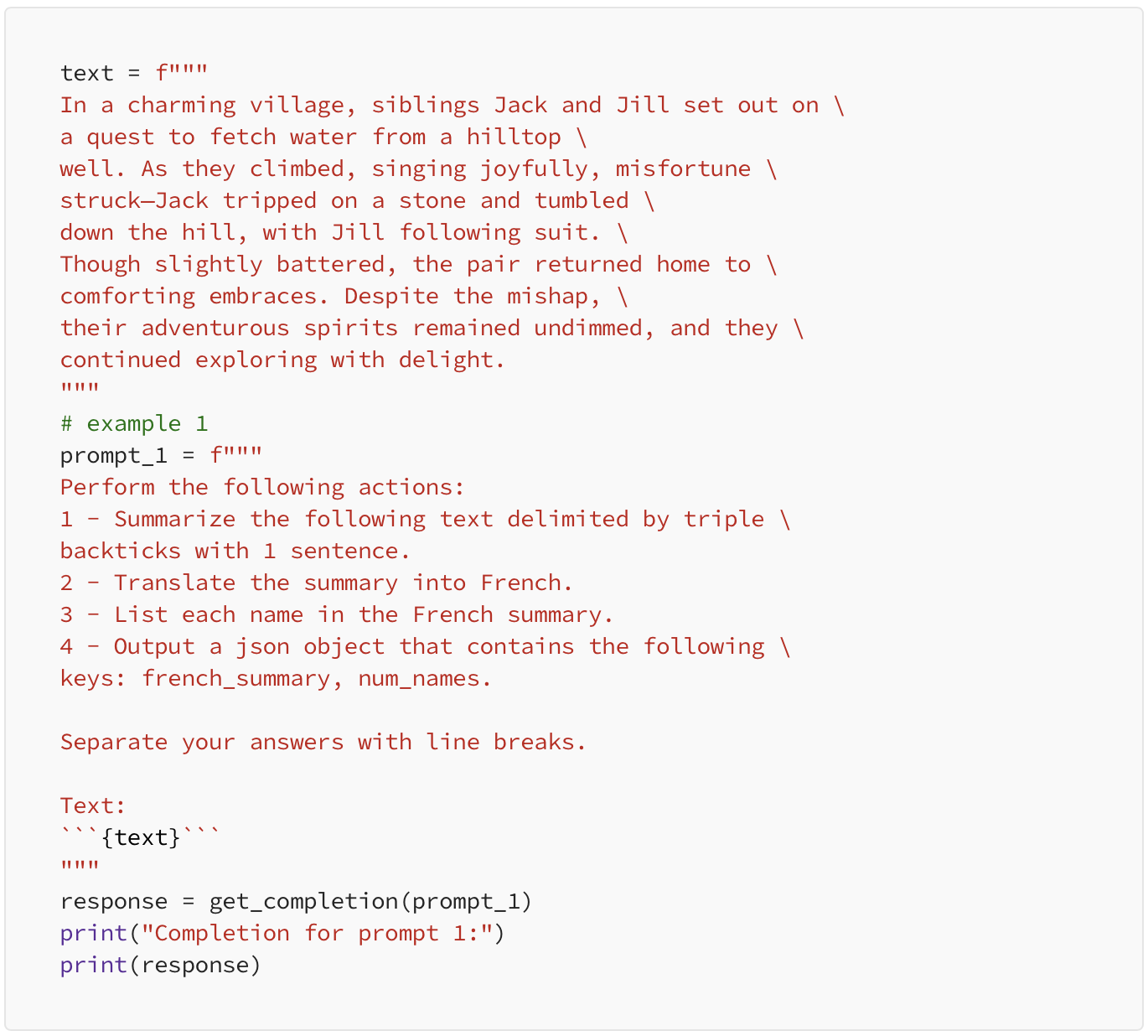
Output

Next, we may use earlier tactic and ask for the output to be in a specified format on the same text.

Output

2. Instruct the model to work out its own solution before rushing to a conclusion.
Let’s ask our model to evaluate a math solution, if it is correct or not.
The below prompt is a math question followed by a solution and the model is directly asked (in the beginning) to determine if the solution is correct or not.

Output

Please solve the problem and you’ll find that the student’s solution is actually not correct and to fix this, we will instruct the model to work out its own solution first and then compare the two results. Note that, when we are instructing the model, we are actually giving it the necessary time to think through the solution.
Below is the updated prompt.

Output

As we give the model enough time to think with specific instructions, the model successfully evaluates the solution and identifies the student’s answer as correct or incorrect.
Bonus principle — Model Limitations: Hallucinations Boie is a real company, the product name is not real.
While developing applications based on Large Language Models, one should always know the limitations of these models. If the model is being exposed to a vast amount of knowledge during its training process, it has not perfectly memorized the information it’s seen, and hence it doesn’t know the boundary of its knowledge very well. This means that the model might try to answer questions about obscure topics and can make things up that sound plausible but are not actually true and these fabricated ideas are called as Hallucinations.
Let’s see with the help of an example of a case where the model will hallucinate something. This is an example of where the model confabulates a description of a made-up product name from a real toothbrush company.
When we give the below prompt as input to our model, it gives us a realistic sounding description of a fictitious product.

Output

this is quite dangerous as the output generated looks very much realistic while it is completely false information.
So, make sure to use the techniques that we’ve gone through in this blog to try to avoid this when you’re building your own applications. This is a known weakness of LLMs and engineers are actively working on combating.
Reducing Hallucinations — First find relevant information, then answer the question based on the relevant information.
In the case that you want the model to generate answers based on a text, first ask the model to find any relevant quotes from the text, then ask it to use those quotes to answer questions and have a way to trace the answer back to the source document.
This tactic is often pretty helpful to reduce these hallucinations.
That’s it, we are done with the basic guidelines, principles and tactics for prompt engineering, in the next article, we will see some common use cases such as summarizing and inferring.
— Author: Rishi Khandelwal
As organizations generate massive amounts of data from various sources, the need for a scalable and cost-effective data storage and processing solution becomes critical. AWS (Amazon Web Services) offers a powerful platform for building a scalable data lake, enabling businesses to store, process, and analyze vast volumes of data efficiently. In this blog, we will dive deep into the process of constructing a robust and scalable data lake on AWS using various services like Amazon S3, AWS Glue, AWS Lambda, and Amazon Athena.
Defining a Data Lake
Before dive in, let's define what a data lake is. A data lake is a central repository that allows organizations to store and process vast amounts of structured and unstructured data at any scale. Unlike traditional databases or data warehouses, a data lake is flexible, capable of accommodating diverse data types, and can scale easily as data volumes increase.
In a data lake, there are entities known as data producers and data consumers. Data producers are responsible for gathering, processing, and storing data within their specific domain, which collectively makes up the content of the data lake. They have the option to share specific data assets with the data consumers of the data lake. Data consumers are users, applications, or systems that retrieve and analyse data from the data lake. They can be data analysts, data scientists, machine learning models, or other downstream processes. Tools like Amazon Athena and Amazon Redshift are used for querying and analysing data within the data lake.
Planning the Data Lake
A scalable data lake architecture establishes a robust framework for organizations to unlock the full potential of its data lake and seamlessly accommodate expanding data volumes. By ensuring uninterrupted data insights, regardless of scale, this architecture enhances your organization's competitiveness in the ever-evolving data landscape.
Efficiently managing data ingestion into data lakes is crucial for businesses as it can be time-consuming and resource-intensive. To optimize cost and extract maximum value from the data, many organizations opt for a one-time data ingestion approach, followed by multiple uses of the same data. To achieve scalability and cater to the increasing data production, sharing, and consumption, a well-thought-out data lake architecture becomes essential. This design ensures that as the data lake expands, it continues to deliver significant value to various business stakeholders.
Having a scalable data lake architecture establishes a strong framework for extracting value from the data lake and accommodating the influx of additional data. This uninterrupted scalability empowers the organization to continuously derive insights from the data without facing constraints, ensuring sustained competitiveness in the market.
Data Variety and Complexity:
As a data lake scales, the variety of data formats and structures also increases. This makes it challenging to maintain a unified data schema and to ensure compatibility across various data sources.
Data Ingestion Performance:
Scaling the data lake can lead to bottlenecks in data ingestion pipelines. High data volumes require efficient and parallelized data ingestion mechanisms.
Data Security and Access Control:
As the data lake grows, managing data access becomes crucial. Ensuring secure access to sensitive data while facilitating easy access for authorized users is a complex task.
Data Quality and Governance:
Maintaining data quality and enforcing governance policies become more difficult at scale. It's essential to have mechanisms to validate, cleanse, and transform data as it enters the lake.
Data Partitioning and Organization:
Proper data partitioning and organization are essential for efficient querying and processing. Without a thoughtful approach, query performance can degrade significantly.
Let's walk through the steps of building a scalable data lake on AWS, addressing the challenges mentioned above.
Amazon S3 Bucket Creation
• Log in to the AWS Management Console and navigate to the S3 service
• Create a new S3 bucket to store the raw data. Choose a unique bucket name, select the desired region, and configure the required settings (e.g., versioning, logging)
• Set up a folder structure within the bucket to organize data by source, date, or any relevant category. This structure helps in managing large volumes of data efficiently
AWS Glue for Data Catalog and ETL
AWS Glue allows us to discover, catalog, and transform data. It creates a metadata repository (Data Catalog) that helps in tracking data and schema changes. Additionally, Glue provides ETL capabilities to convert raw data into structured formats for querying.
• Go to the AWS Glue service in the AWS Management Console
• Create a new Glue Data Catalog database and relevant tables based on your data structure
• Define Glue ETL jobs using Python or Scala code to transform the data into a desired format.
• Here's an example of a Glue ETL job using Python:

Amazon Athena for Querying Data
Amazon Athena allows you to perform ad-hoc SQL queries on the data stored in S3 without the need for any data transformation upfront. It enables you to gain insights directly from the raw data.
• Go to the Amazon Athena service in the AWS Management Console
• Create a new database and corresponding tables in Athena using the Glue Data Catalog
• Write SQL queries to analyse and extract insights from the data. For example;

Data Ingestion into the Data Lake
Batch Data Ingestion
To ingest data into the Data Lake, you can use various methods, such as AWS DataSync, AWS Transfer Family, or AWS Glue DataBrew for data preparation. For batch data ingestion, AWS Glue ETL jobs can be scheduled to run periodically or triggered by specific events. Example of using AWS Glue DataBrew for batch data ingestion:

Real-time Data Ingestion
For real-time data ingestion, you can use services like Amazon Kinesis or AWS Lambda. Here's an example of using AWS Lambda to ingest real-time data into the Data Lake:

Defining Schema and Data Types
It is essential to define the schema and data types for the data stored in the Data Lake. This helps in ensuring consistent data and enables better query performance. You can use tools like AWS Glue Crawler to automatically infer the schema from the data, or you can provide a schema manually.
Data Cleaning and Standardization
Before performing analytics, it's crucial to clean and standardize the data to remove any inconsistencies and ensure data quality. You can achieve this through AWS Glue ETL jobs, using Spark transformations or Python functions.
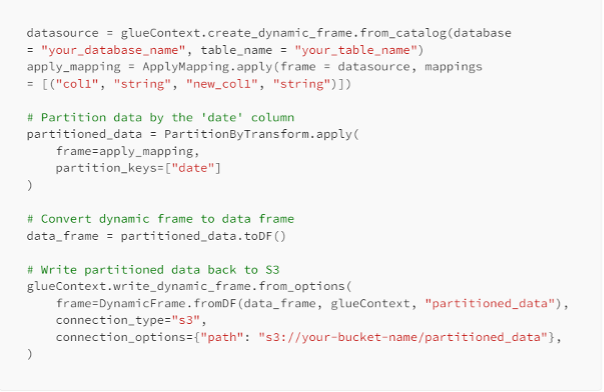
Partitioning Data for Performance
Partitioning data in the Data Lake helps improve query performance, especially for large datasets. It allows for faster data retrieval and reduces the data scan size. You can partition data based on relevant columns like date, region, or category.
Example of partitioning data in AWS Glue ETL job:
IAM Policies
AWS Identity and Access Management (IAM) policies help manage permissions and access to AWS resources. Ensure that you have defined appropriate IAM policies to control access to S3 buckets, Glue Data Catalog, and other services.
Example of an IAM policy for a user with access to specific S3 buckets:

S3 Bucket Policies
S3 bucket policies allow fine-grained control over access to the bucket and its objects. You can define policies to grant specific permissions to specific users or groups.
Example of an S3 bucket policy allowing read access to specific IAM users:

Amazon Redshift for Data Warehousing
For advanced analytics and data warehousing, you can integrate Amazon Redshift with your Data Lake. Amazon Redshift provides a high-performance data warehouse that allows you to run complex SQL queries and perform OLAP (Online Analytical Processing) tasks.

Amazon QuickSight for Data Visualization
Amazon QuickSight offers an easy-to-use business intelligence tool that enables you to create interactive dashboards and visualizations from data in your Data Lake.
Example of creating a QuickSight dashboard:
• Connect QuickSight to your Data Lake by creating a dataset
• Choose the relevant data tables from the Data Catalog.
Use the drag-and-drop interface to create visualizations and assemble them into a dashboard.
Data Governance and Compliance
Ensure that your Data Lake adheres to data governance and compliance standards, especially if you deal with sensitive or regulated data. Implement encryption mechanisms for data at rest and in transit, and apply access control to restrict data access to authorized users only.
Data Lake Monitoring and Scaling
Implement monitoring and logging mechanisms to track the performance, health, and usage of your Data Lake components. Use AWS CloudWatch for monitoring and set up alarms for critical metrics.
Additionally, design your Data Lake to scale effectively with growing data volumes. AWS services like S3 and Glue are designed to handle large-scale data, but it's essential to optimize your data storage and processing to ensure smooth performance.
Conclusion
Building a scalable data lake using AWS S3, Glue, and Lake Formation empowers organizations to handle vast amounts of data and extract valuable insights. With the steps and code examples provided in this blog post, you have the foundation to create a powerful data lake architecture that supports data-driven decision-making and analytics.
By following these best practices and utilizing AWS services, you can overcome the challenges of scaling a data lake and build a robust, scalable, and efficient data infrastructure that empowers your organization to extract valuable insights from your data.
Remember that data lake implementations can vary based on specific use cases and requirements. Be sure to continuously monitor and optimize your data lake architecture to make the most of AWS's powerful services.
— Yasir UI Hadi
References
https://docs.aws.amazon.com/prescriptive-guidance/latest/data-lake-for-growth-scale/welcome.html
https://aws.amazon.com/solutions/implementations/data-lake-solution/
In the world of healthcare data analytics, the challenge lies in making use of the vast amount of unstructured data that constitutes approximately 80% of all healthcare data [NCBI]. This unstructured data includes a variety of sources such as physician notes, prescription reports, lab reports, patient discharge summaries, and medical images, among others. While this data was never originally intended to be structured, the digital transformation revolution has motivated healthcare providers to harness its potential, leading to enhanced revenue streams, streamlined processes, and improved customer satisfaction [2].
However, the task of converting unstructured healthcare data into structured formats is no easy feat. Take, for instance, prescription reports or clinical notes – their complexity and heterogeneity make it difficult to fit them neatly into traditional databases and data tables like Excel or CSV files. The presence of inconsistent and cryptic medical terminologies further complicates the conversion process. Moreover, clinical jargon, acronyms, misspellings, and abbreviations add to the challenges faced during the conversion.
Despite these complexities, embracing the digital era revolution requires overcoming these hurdles. The abundance of unstructured medical data demands its effective utilization in analytics. By converting this data into structured or semi-structured formats, we can unlock its potential for advance analytics.
SOLUTION OVERVIEW:
The process of converting unstructured data into structured/semi-structured data involves several steps, including data extraction from documents, data cleaning and pre-processing, data mapping, data standardization, and data normalization. After these steps have been completed, the data is typically stored, analysed, and used to generate insights. This article delves into the process and its challenges, providing several examples to illustrate the application of these techniques on a sample dataset.
AWS offers an array of tools and services to assist healthcare providers in unlocking the full potential of their data. Our solution utilizes various AWS services like Amazon Textract to process a small sample of documents, extracting relevant data and converting it into FHIR resources within Amazon HealthLake to do analytics and ML modelling using Amazon SageMaker.
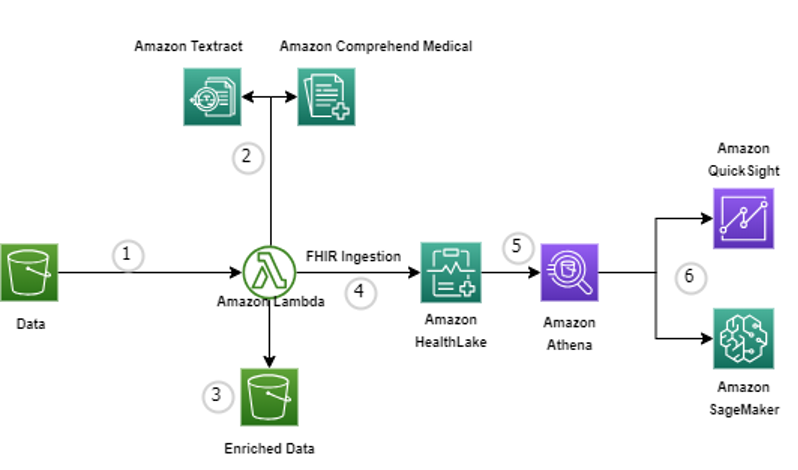
DATA EXTRACTION:
The foundation of utilizing unstructured healthcare data lies in the extraction of relevant information from various sources like images, PDFs, and scanned documents. This process involves leveraging the power of Optical Character Recognition (OCR) algorithms and tools, such as the widely available services like Amazon Textract. These algorithms and tools enable us to recognize, extract, and define output from the unstructured data, making it machine-readable and ready for further analysis
For example, I have taken a sample lab investigation report and ran Textract to get the extracted information in the CSV or Excel format.
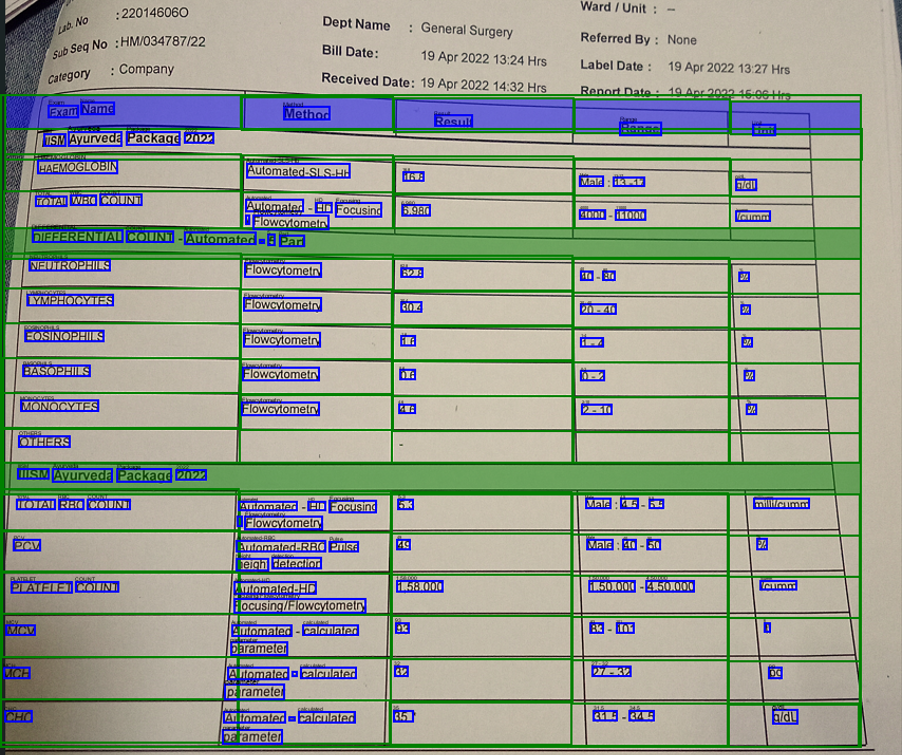
The corresponding output file of the unstructured document:
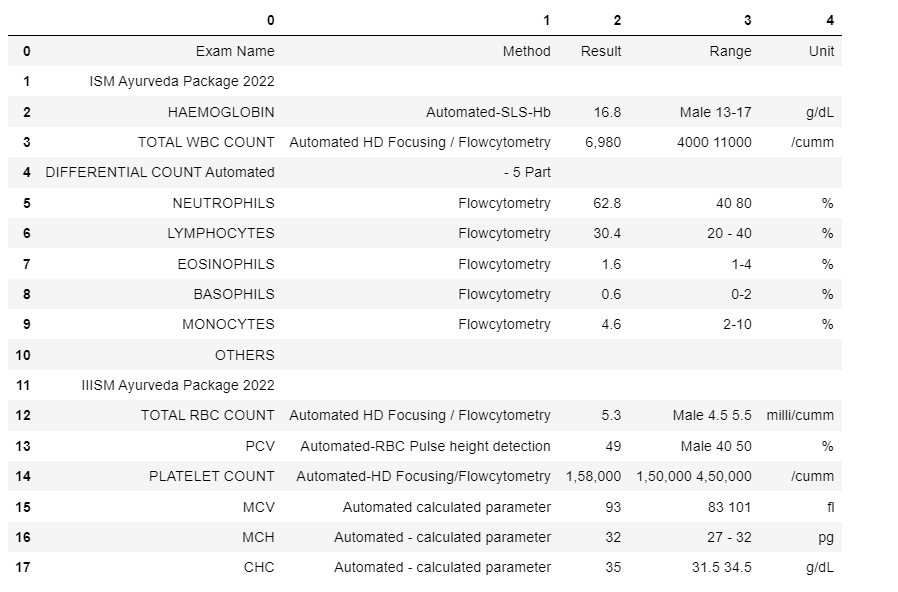
DATA PRE-PROCESSING
Once the data is extracted, the challenge lies in standardizing it to a uniform format for meaningful comparison and calculations. Natural Language Processing (NLP) techniques play a vital role in extracting valuable information from textual data. Services like Amazon Comprehend Medical can effectively handle entity recognition and identify standards within the data, making it easier for healthcare providers to interpret diagnoses, symptoms, treatments, and other crucial information.
For example, when we provide the Amazon Comprehend Medical some clinical information, it extracts the entities and tags them with various inbuilt attributes, as can be seen in the green-coloured highlights.
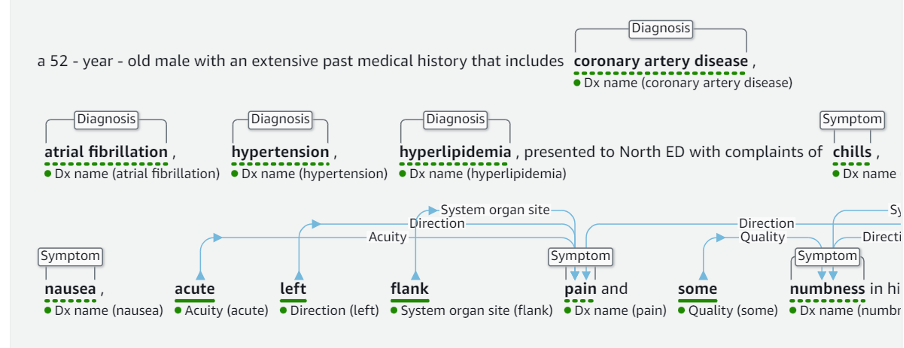
This process highlights certain things that a healthcare provider might need to look from the complete document and this recognition also provides us with a mapping of what were the diagnoses, symptoms, treatments and qualities etc.
DATA MAPPING, NORMALIZATION, & STANDARDIZATION
The extracted data is diverse and needs to be transformed to a common scale to facilitate meaningful comparison and calculations. Additionally, it is crucial to standardize terminology to ensure homogeneity of medical concepts across different datasets. Furthermore, data ontology plays a crucial role in establishing a common ground for understanding the data, thereby enhancing the accuracy and relevance of analyses by defining the relationships between different medical concepts.
In the healthcare domain, various coding systems have been utilized since the 1960s, including ICD, SNOMED CT, LOINC, and the most recent HL7 FHIR format. Mapping these unstructured data elements to these standards allows for a common understanding of medical concepts, which is crucial for data integration and interoperability.
We can convert and map the data into FHIR format for off-the-shelf analytics using Amazon HealthLake.
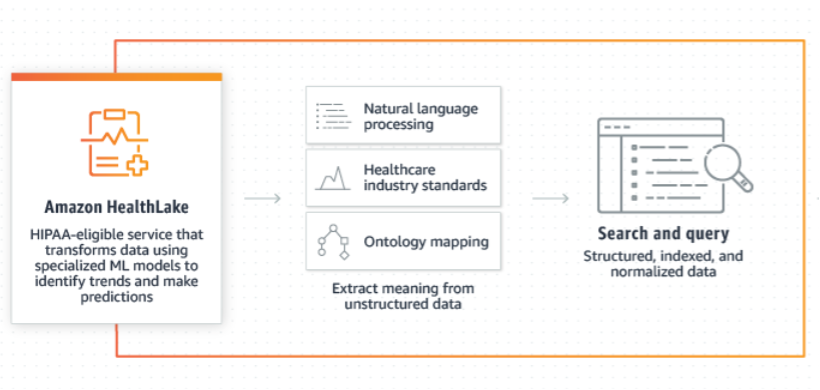
ANALYTICS:
We have successfully extracted, cleansed, and pre-processed the data stored in the Amazon HealthLake in the FHIR format. As a result, it is now structured and ready to be queried using Amazon Athena. We will proceed with conducting descriptive analysis of the patient data to gain insights into their current health status. We will use Amazon QuickSight to create dashboards that visualize the medical data.
For instance, we have patient lab investigation reports, and we have extracted the information along with unique identifiers such as UHID. We have performed the necessary preliminary steps to ensure that the data is usable.
Our descriptive analytics will involve creating a dashboard that displays vitals trends, health parameters abnormalities, a timeline view of medical events, the distribution of normality, and the classification of parameters based on abnormality. We will also include a health parameter value change indicator to compare the changes during a specific period.
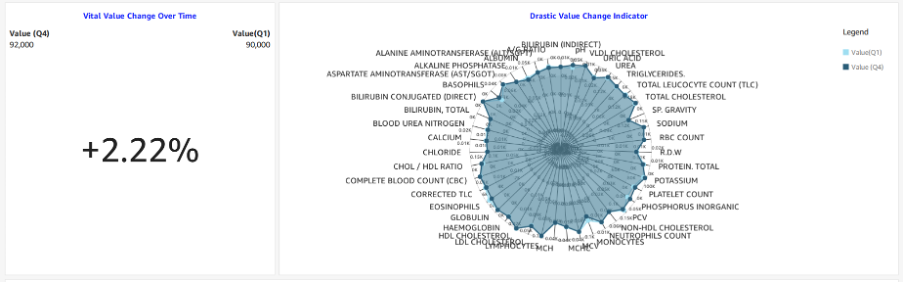

Once the data has been successfully extracted, cleaned, and pre-processed, advanced machine learning algorithms come into play. These powerful techniques enable healthcare professionals to determine patterns, trends. And correlations within the data, providing valuable insights into patient health and potential medical outcomes. By training predictive models on historical data, healthcare providers can forecast disease progression, identify high-risk patients, and even anticipate potential health complications, as I previously talked about in this article.
Additionally, predictive analytics empowers personalized care by tailoring treatment plans to individual patient needs, optimizing interventions, and ultimately leading to improved patient outcomes.
For example, in order to identify chronic kidney disease (CKD) at an early stage, it is important to monitor various factors such as the individual’s eGFR level, age, lifestyle, and other relevant indicators. Once this information has been gathered, machine-learning techniques can be utilized to aid in the detection process.
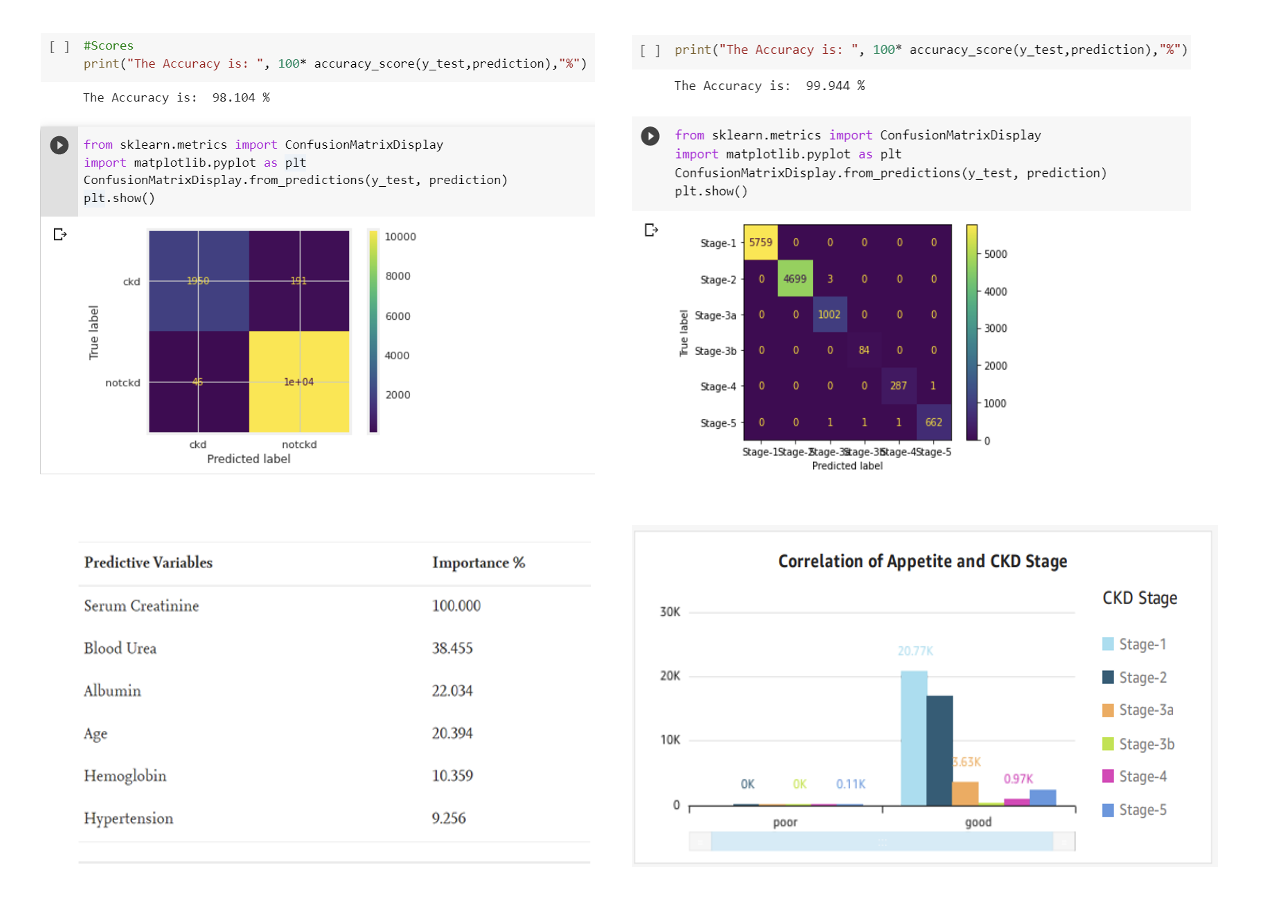
In the pursuit of leveraging unstructured healthcare data through advanced analytics, we face daunting challenges. However, by conquering complexity through data extraction, pre-processing, and standardization, an unknown world of insights awaits.
~ Author: Gaurav Lohkna
RESOURCES AND REFERENCES
Kong, H.-J. (2019). Managing Unstructured Big Data in Healthcare System. Healthcare Informatics Research, 25(1), https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6372467/
SyTrue (2015). Why Unstructured Data Holds the Key to Intelligent Healthcare Systems. [online] hitconsultant.net. Available at: https://hitconsultant.net/2015/03/31/tapping-unstructured-data-healthcares-biggest-hurdle-realized/
Image Source: https://treehousetechgroup.com/structured-data-vs-unstructured-data-whats-the-difference/
Mentioned Blog: https://www.minfytech.com/tackling-chronic-kidney-disease/
This website stores cookie on your computer. These cookies are used to collect information about how you interact with our website and allow us to remember you. We use this information in order to improve and customize your browsing experience and for analytics and metrics about our visitors both on this website and other media. To find out more about the cookies we use, see our Privacy Policy. If you decline, your information won’t be tracked when you visit this website. A single cookie will be used in your browser to remember your preference not to be tracked.