 Go to Swayam
Go to Swayam- Home
- About
- Consulting
- Services
- Minfy Labs
- Industries
- Resonances
- Careers
- Contact
What is predictive maintenance and how does it work?
Artificial intelligence (AI) is transforming the energy and resources industry in many ways, including predictive maintenance. AI powered predictive maintenance is a data-driven approach that uses machine learning (ML) algorithms to address some of the crucial challenges related to machine maintenance.
The energy industry is heavily reliant on machinery and equipment. These assets are critical for operations and require ongoing maintenance to operate effectively. Traditional maintenance approaches, such as reactive or scheduled maintenance, can be costly and inefficient.
Reactive maintenance involves fixing equipment after a breakdown has occurred, leading to costly downtime and repairs whereas scheduled maintenance involves conducting maintenance at set intervals, regardless of the condition of the equipment leading to unnecessary maintenance and downtime.
Both these methods of performing maintenance are not smart and leads to wastage of resources.
Predictive maintenance, on the other hand, uses data to predict when equipment is likely to fail and schedule maintenance accordingly. This approach can help companies reduce downtime, extend the life of equipment, and increase safety. AI and ML algorithms are used to analyse data from sensors and other sources to identify patterns and anomalies. Predictive ML models are then developed to predict when maintenance will be required.
Now, let’s look at what can be achieved using AI powered predictive maintenance solutions.
First, we need to understand what type of data is involved in the process. Generally, there are two types of data involved in building such systems.
1. Images
2. Sensors’ reading – analogue signals and numbers
This data is used to answer three types of questions which leads to three different use cases.
1. Is the machine behaving abnormally? – Anomaly detection
2. Is there a fault in my system? And what is the root cause? – fault classification or root cause isolation
3. When is the machine likely to encounter a fault condition? – Remaining useful life estimation.
Once we have clarity on what we want to achieve using predictive maintenance solution, it is time to move onto the next steps of building the solution.
Developing the solution involves multiple steps described below.
1. Data acquisition – Collecting relevant data to solve a problem is the base of any machine learning solution. Data is collected either from the sensors attached to the equipment or from images captured during operation.
2. Data analysis – Once the data is stored, it is analysed using signal processing techniques (extracting, manipulating, and storing information embedded in complex signals and images) and desired features are extracted from it.
3. Modelling – Once the data type and the problem statement is clear, we can make a choice and select the right type of ML algorithm. For example, while working with image data, we can use deep neural network-based architecture such as Convolutional Neural Network (CNN) to classify if the equipment is damaged or not. Once the training process is complete, next we set up an inferencing pipeline which is used to query from the model.
Generally we use CNNs with image input. It’s not clear what you mean by automating feature selection from image data. For fault detection do we need something like semantic segmentation? If yes you need to explain that.
Let’s talk about key considerations with building AI powered predictive maintenance solution -
• Data collection – We need enough data to cover all the use cases we want our solution to deliver. Data corresponding to fault or failure conditions is usually difficult to obtain as the incidents of failures are relatively few. One way to solve this problem is by simulating scenarios to capture fake failure . Another way is using existing failure data to create more failure data using machine learning.
• Data engineering and analysis – Managing large amounts of data cost efficiently is a challenging task. Machine sensors might produce data in GBs every day, and to process, store and analyse this data requires robust data pipelines.
• Feature extraction – The data which will be used for training the ML models should contain maximum information and minimum noise. If the features are not relevant to the problem, resources will get wasted in training models with such data. So, subject matter expertise is important to extract as much information as possible while reducing the size of the data set.
In the energy and resources industry, predictive maintenance can be used for a wide range of equipment, including turbines, compressors, pumps, and generators. Let’s have a look at some of these examples.
• Predictive maintenance to monitor the condition of wind turbines – Data from sensors on the turbines is used to monitor parameters such as temperature, vibration, and oil levels. ML models can then analyse this data to predict when maintenance will be required. This can help companies schedule maintenance during periods of low wind activity, reducing downtime and increasing energy production.
• Predictive maintenance to monitor the condition of pipelines and other infrastructure – Data from sensors placed along pipelines is used to monitor parameters such as pressure, temperature, and flow rate. ML models can then analyze this data to predict when maintenance will be required. This can help companies identify potential leaks or failures before they occur, reducing the risk of accidents and downtime.
Here’s an example of how to leverage AI to predict Remaining Useful Life (RUL) for an equipment.
We can build, deploy and scale AI powered solutions on AWS. Below is one such solution for predicting remaining useful life of an equipment.
The example uses Amazon SageMaker to train a deep learning ML model with the MXNet deep learning framework. The model is a stacked bidirectional LSTM neural network that can learn from sequential or time series data. The model is robust to the input dataset and does not expect the sensor readings to be smoothed, as the model has 1D convolutional layers with trainable parameter that can smooth and perform feature transformation of the time series. The deep learning model is trained so that it learns to predict the remaining useful life (RUL) for each sensor
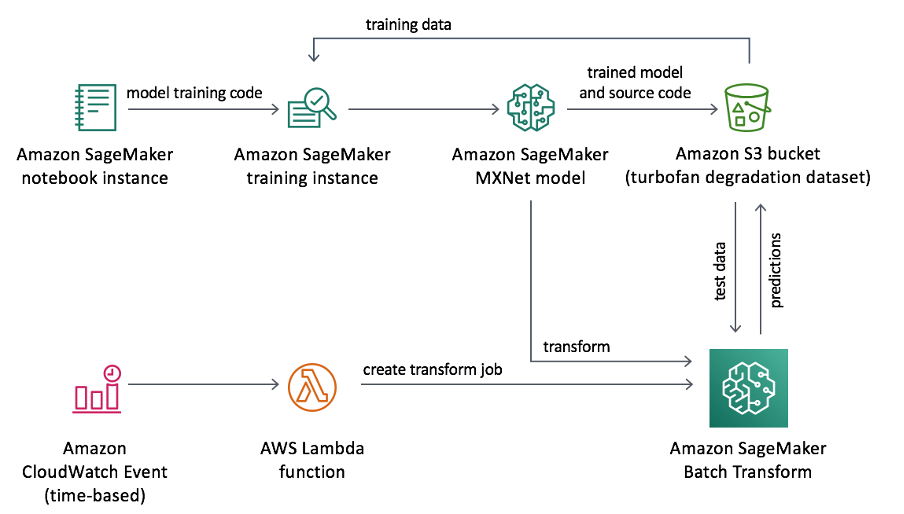
The historical sensor data is stored in S3 bucket and from here it will be used to train the deep learning model
Training
• Once the training data is stored in a S3 Bucket, model training code is written in a Jupyter notebook running on an Amazon Sagemaker notebook instance.
• The MXNet model is trained and the model artifacts are stored in a S3 bucket.
Inferencing
• AWS Lambda function is included to perform batch inference on new data that comes from sensors and is stored in an Amazon S3 bucket
• The Lambda function can be invoked by an AWS CloudWatch Event or with a S3 put event notification so that it runs on a schedule or as soon as new sensor readings are stored in S3
• When invoked, the Lambda function creates a Sagemaker Batch Transform job, which uses the Sagemaker Model that was saved during training, to obtain model predictions for the new sensor data
• The results of the batch transform job are stored back in S3, and can be fed into a dashboard or visualization module for monitoring
To conclude, if there is enough sensor data available, we can harness its power and shift from a reactive/scheduled method to AI powered predicitive maintenance. Amazon Web Services accelerates the process of building such solutions. This will help companies save on their operations by cutting down on their maintenance cost and improving overall reliability of the system.
— Author: Rishi Khandelwal
This website stores cookie on your computer. These cookies are used to collect information about how you interact with our website and allow us to remember you. We use this information in order to improve and customize your browsing experience and for analytics and metrics about our visitors both on this website and other media. To find out more about the cookies we use, see our Privacy Policy. If you decline, your information won’t be tracked when you visit this website. A single cookie will be used in your browser to remember your preference not to be tracked.