 Go to Swayam
Go to Swayam- Home
- About
- Consulting
- Services
- Minfy Labs
- Industries
- Resonances
- Careers
- Contact
In the world of healthcare data analytics, the challenge lies in making use of the vast amount of unstructured data that constitutes approximately 80% of all healthcare data [NCBI]. This unstructured data includes a variety of sources such as physician notes, prescription reports, lab reports, patient discharge summaries, and medical images, among others. While this data was never originally intended to be structured, the digital transformation revolution has motivated healthcare providers to harness its potential, leading to enhanced revenue streams, streamlined processes, and improved customer satisfaction [2].
However, the task of converting unstructured healthcare data into structured formats is no easy feat. Take, for instance, prescription reports or clinical notes – their complexity and heterogeneity make it difficult to fit them neatly into traditional databases and data tables like Excel or CSV files. The presence of inconsistent and cryptic medical terminologies further complicates the conversion process. Moreover, clinical jargon, acronyms, misspellings, and abbreviations add to the challenges faced during the conversion.
Despite these complexities, embracing the digital era revolution requires overcoming these hurdles. The abundance of unstructured medical data demands its effective utilization in analytics. By converting this data into structured or semi-structured formats, we can unlock its potential for advance analytics.
SOLUTION OVERVIEW:
The process of converting unstructured data into structured/semi-structured data involves several steps, including data extraction from documents, data cleaning and pre-processing, data mapping, data standardization, and data normalization. After these steps have been completed, the data is typically stored, analysed, and used to generate insights. This article delves into the process and its challenges, providing several examples to illustrate the application of these techniques on a sample dataset.
AWS offers an array of tools and services to assist healthcare providers in unlocking the full potential of their data. Our solution utilizes various AWS services like Amazon Textract to process a small sample of documents, extracting relevant data and converting it into FHIR resources within Amazon HealthLake to do analytics and ML modelling using Amazon SageMaker.
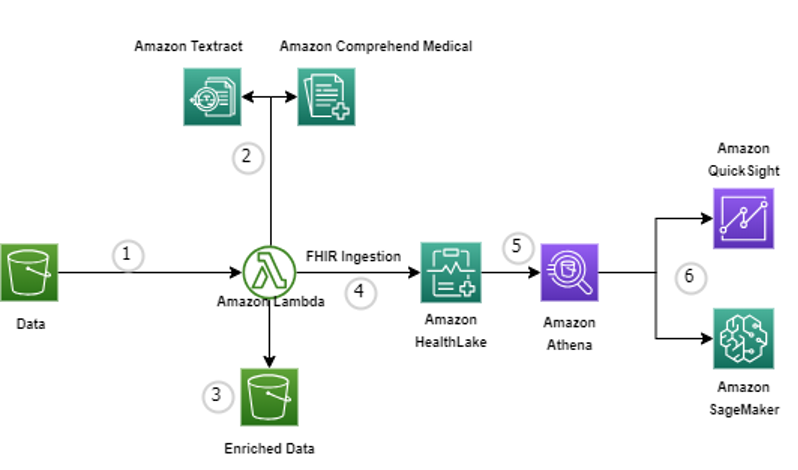
DATA EXTRACTION:
The foundation of utilizing unstructured healthcare data lies in the extraction of relevant information from various sources like images, PDFs, and scanned documents. This process involves leveraging the power of Optical Character Recognition (OCR) algorithms and tools, such as the widely available services like Amazon Textract. These algorithms and tools enable us to recognize, extract, and define output from the unstructured data, making it machine-readable and ready for further analysis
For example, I have taken a sample lab investigation report and ran Textract to get the extracted information in the CSV or Excel format.
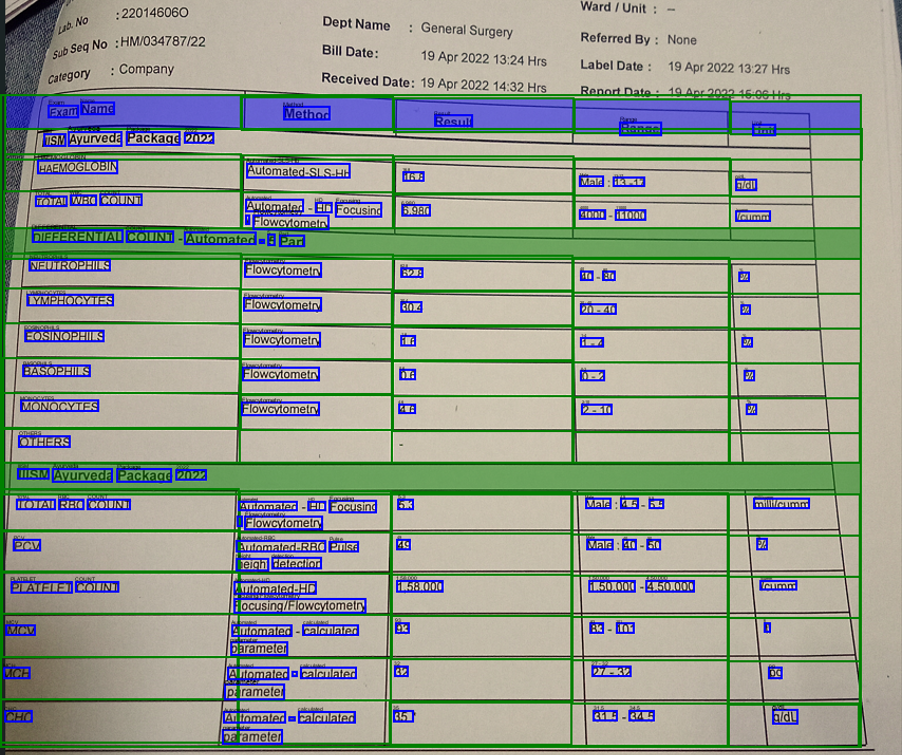
The corresponding output file of the unstructured document:
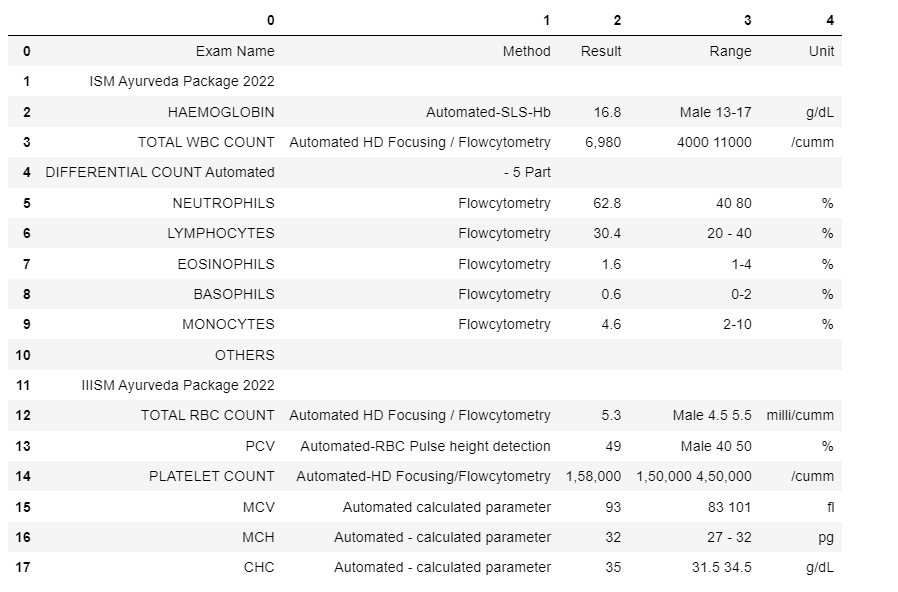
DATA PRE-PROCESSING
Once the data is extracted, the challenge lies in standardizing it to a uniform format for meaningful comparison and calculations. Natural Language Processing (NLP) techniques play a vital role in extracting valuable information from textual data. Services like Amazon Comprehend Medical can effectively handle entity recognition and identify standards within the data, making it easier for healthcare providers to interpret diagnoses, symptoms, treatments, and other crucial information.
For example, when we provide the Amazon Comprehend Medical some clinical information, it extracts the entities and tags them with various inbuilt attributes, as can be seen in the green-coloured highlights.
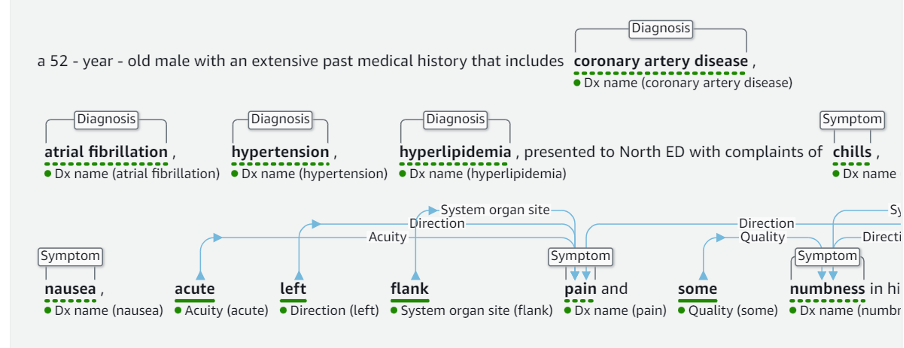
This process highlights certain things that a healthcare provider might need to look from the complete document and this recognition also provides us with a mapping of what were the diagnoses, symptoms, treatments and qualities etc.
DATA MAPPING, NORMALIZATION, & STANDARDIZATION
The extracted data is diverse and needs to be transformed to a common scale to facilitate meaningful comparison and calculations. Additionally, it is crucial to standardize terminology to ensure homogeneity of medical concepts across different datasets. Furthermore, data ontology plays a crucial role in establishing a common ground for understanding the data, thereby enhancing the accuracy and relevance of analyses by defining the relationships between different medical concepts.
In the healthcare domain, various coding systems have been utilized since the 1960s, including ICD, SNOMED CT, LOINC, and the most recent HL7 FHIR format. Mapping these unstructured data elements to these standards allows for a common understanding of medical concepts, which is crucial for data integration and interoperability.
We can convert and map the data into FHIR format for off-the-shelf analytics using Amazon HealthLake.
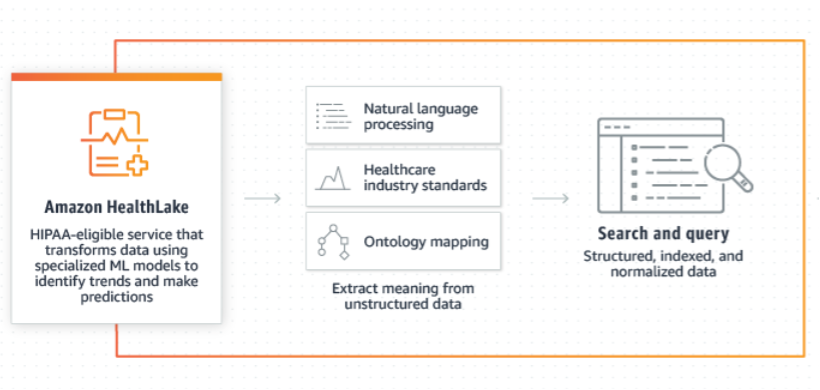
ANALYTICS:
We have successfully extracted, cleansed, and pre-processed the data stored in the Amazon HealthLake in the FHIR format. As a result, it is now structured and ready to be queried using Amazon Athena. We will proceed with conducting descriptive analysis of the patient data to gain insights into their current health status. We will use Amazon QuickSight to create dashboards that visualize the medical data.
For instance, we have patient lab investigation reports, and we have extracted the information along with unique identifiers such as UHID. We have performed the necessary preliminary steps to ensure that the data is usable.
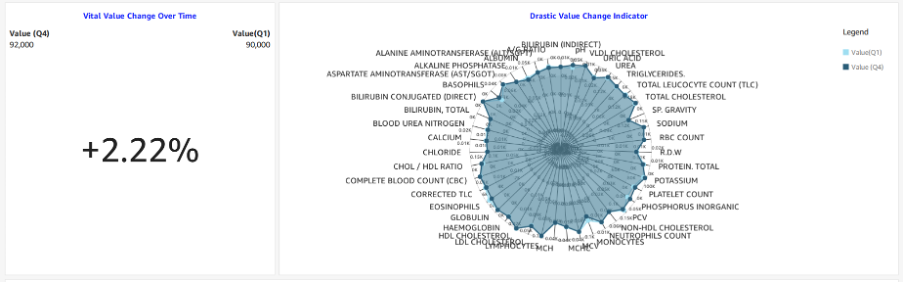
Our descriptive analytics will involve creating a dashboard that displays vitals trends, health parameters abnormalities, a timeline view of medical events, the distribution of normality, and the classification of parameters based on abnormality. We will also include a health parameter value change indicator to compare the changes during a specific period.

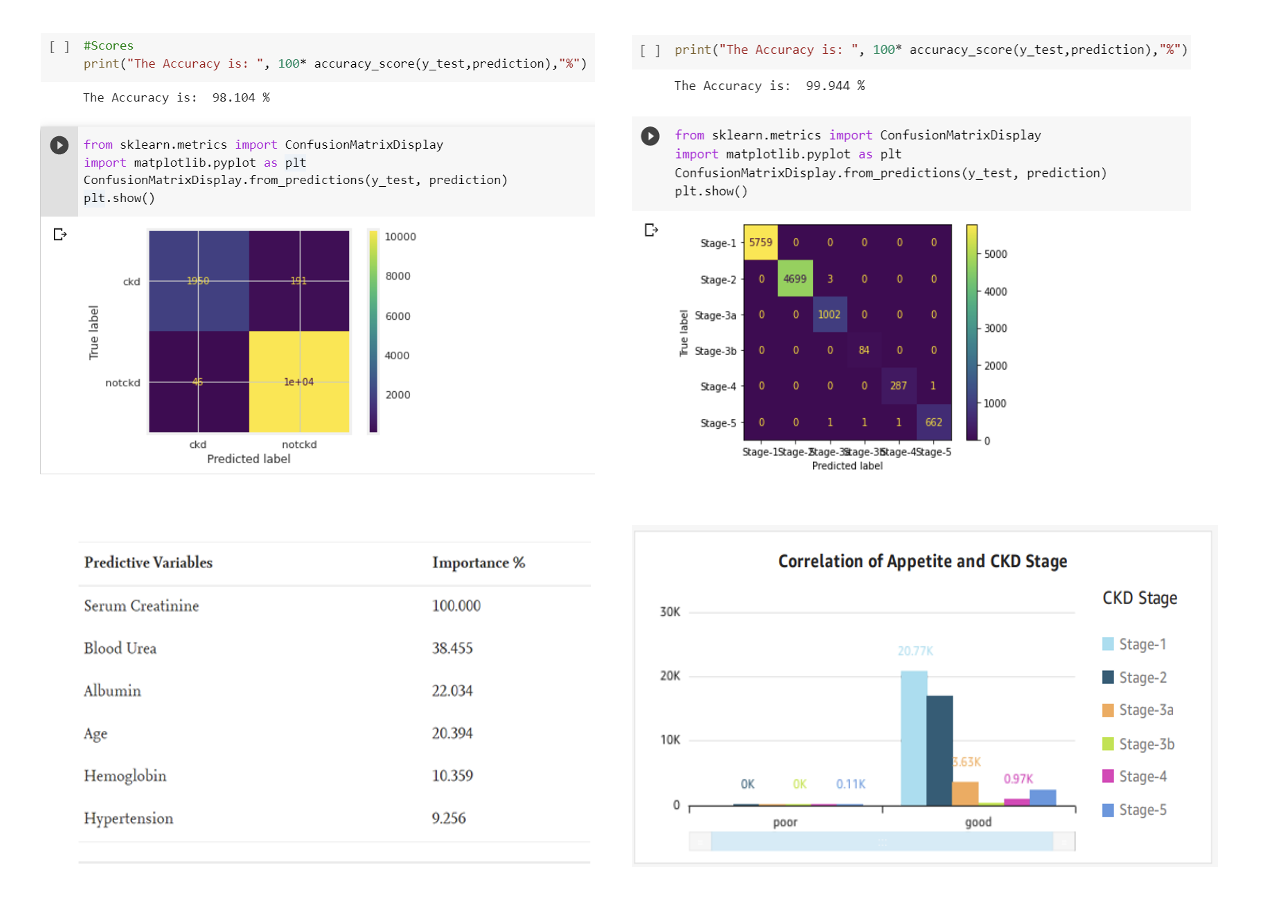
Once the data has been successfully extracted, cleaned, and pre-processed, advanced machine learning algorithms come into play. These powerful techniques enable healthcare professionals to determine patterns, trends. And correlations within the data, providing valuable insights into patient health and potential medical outcomes. By training predictive models on historical data, healthcare providers can forecast disease progression, identify high-risk patients, and even anticipate potential health complications, as I previously talked about in this article.
Additionally, predictive analytics empowers personalized care by tailoring treatment plans to individual patient needs, optimizing interventions, and ultimately leading to improved patient outcomes.
For example, in order to identify chronic kidney disease (CKD) at an early stage, it is important to monitor various factors such as the individual’s eGFR level, age, lifestyle, and other relevant indicators. Once this information has been gathered, machine-learning techniques can be utilized to aid in the detection process.
In the pursuit of leveraging unstructured healthcare data through advanced analytics, we face daunting challenges. However, by conquering complexity through data extraction, pre-processing, and standardization, an unknown world of insights awaits.
~ Author: Gaurav Lohkna
RESOURCES AND REFERENCES
Kong, H.-J. (2019). Managing Unstructured Big Data in Healthcare System. Healthcare Informatics Research, 25(1), https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6372467/
SyTrue (2015). Why Unstructured Data Holds the Key to Intelligent Healthcare Systems. [online] hitconsultant.net. Available at: https://hitconsultant.net/2015/03/31/tapping-unstructured-data-healthcares-biggest-hurdle-realized/
Image Source: https://treehousetechgroup.com/structured-data-vs-unstructured-data-whats-the-difference/
Mentioned Blog: https://www.minfytech.com/tackling-chronic-kidney-disease/
This website stores cookie on your computer. These cookies are used to collect information about how you interact with our website and allow us to remember you. We use this information in order to improve and customize your browsing experience and for analytics and metrics about our visitors both on this website and other media. To find out more about the cookies we use, see our Privacy Policy. If you decline, your information won’t be tracked when you visit this website. A single cookie will be used in your browser to remember your preference not to be tracked.