Introduction
Machine learning is revolutionizing various industries, but its successful implementation is not just limited to building the perfect model. MLOps, which stands for Machine Learning Operations, is an approach that addresses the entire machine learning lifecycle, from development to deployment and beyond. MLOps helps businesses and industries scale their machine learning workloads by streamlining the process of building, deploying, monitoring, and updating machine learning models.
What is MLOps?
MLOps, which stands for Machine Learning Operations, is a practice that involves the application of DevOps principles to machine learning workflows. It aims to streamline and automate the development, deployment, monitoring, and management of machine learning models.
MLOps helps to bridge the gap between data science and deployment operations, enabling businesses to build, train, deploy and monitor machine learning models more efficiently. It is not a specific tool or technology but rather a set of practices, methodologies, and tools that are used to support the entire machine learning lifecycle.
MLOps Workflow
MLOps workflows typically include the following stages:
• Data preparation: collecting and cleaning the data for use in model training and evaluation.
• Model training: selecting the appropriate algorithm and training the model on the prepared data.
• Model evaluation: assessing the performance of the trained model and identifying areas for improvement.
• Model deployment: deploying the model to production environment.
• Model monitoring: monitoring the model's performance in production environment and adjusting as needed.
Why is MLOps important?
MLOps is important because it enables businesses to scale their machine learning workloads in a way that is efficient, reliable, and secure. By applying DevOps principles to machine learning workflows, MLOps helps businesses to:
Reduce development time and costs:
By automating the machine learning workflow, MLOps reduces the time and effort required to develop, test, and deploy models. This results in faster time-to-market and lower development costs.
Improve model accuracy:
MLOps enables businesses to continually monitor and improve the performance of their machine learning models in production environment, resulting in more accurate and reliable models.
Increase security:
MLOps ensures that machine learning models are deployed in a secure environment and that the data used to train the models is protected.
Enable collaboration:
MLOps fosters collaboration between data scientists, IT operations, and other stakeholders involved in the machine learning workflow, resulting in better communication and teamwork.
Scale machine learning infrastructure:
MLOps helps businesses to scale their machine learning infrastructure in a way that is efficient and reliable, enabling them to handle increasing amounts of data and models.
How to deploy machine learning models with high efficiency and scalability in a production environment?[i]
Amazon SageMaker is a great place for automating the complete end-to-end process of the model development and deployment through the interactive UI which AWS provides in the SageMaker resources.
1. Create repeatable training workflows to accelerate model development
One important aspect of MLOps is creating repeatable training workflows that can accelerate model development.
In SageMaker, you can use several features to create a repeatable training workflow, including:
• SageMaker Experiments: SageMaker Experiments lets you track and compare the results of your machine learning experiments, enabling you to quickly identify the most effective models and hyperparameters.
• SageMaker Processing: SageMaker Processing lets you run pre-processing, postprocessing, and other data processing tasks on large datasets in a distributed and scalable way. This helps ensure that your data is consistently processed and prepared for training.
• SageMaker Training: SageMaker Training lets you train machine learning models on large datasets using distributed computing resources. You can use built-in algorithms or bring your own custom algorithms to SageMaker.
• SageMaker Debugger: SageMaker Debugger lets you identify and debug training errors in real time. You can monitor the state of your training job and capture specific events, such as null values or weights that are too large.
2. Catalogue ML artifacts centrally for model reproducibility and governance
Cataloguing ML artifacts centrally is an essential step towards achieving model reproducibility and governance. In machine learning (ML), artifacts are produced during the model training process, such as code, datasets, models, and configurations. Cataloguing them centrally means storing them in a centralized location where they can be easily accessed, tracked, and managed.
There are several benefits to cataloguing ML artifacts centrally such as Reproducibility, Governance, Collaboration, etc.
Amazon SageMaker provides several tools for cataloguing ML artifacts centrally, including:
• SageMaker Model Registry: A managed service that provides a central location for storing, versioning, and sharing ML models. With the Model Registry, data scientists can easily track changes to their models, compare different versions, and promote models to production.
• SageMaker Pipelines: A workflow automation tool that helps data scientists build, deploy, and manage ML workflows. Pipelines allow data scientists to define a series of steps for training and deploying models, and then execute those steps as a single unit.
• SageMaker Experiments: A service that helps data scientists track, organize, and analyse their ML experiments. With Experiments, data scientists can easily capture metadata about their experiments, including code, data, hyperparameters, and metrics.
3. Integrate ML workflows with CI/CD pipelines for faster time to production
Amazon SageMaker provides a set of tools and features that make it easy to integrate machine learning (ML) workflows with Continuous Integration and Continuous Deployment (CI/CD) pipelines, enabling faster time to production for ML models.
CI/CD pipelines are a set of practices and tools that enable developers to quickly and reliably build, test, and deploy code changes to production environments. By integrating ML workflows with CI/CD pipelines, data scientists can automate the process of building, testing, and deploying ML models, reducing the time and effort involved and increasing the speed at which models are delivered to production.
Here are some of the ways in which SageMaker enables the integration of ML workflows with CI/CD pipelines:
• SageMaker Model Building Pipelines: SageMaker Model Building Pipelines is a feature of SageMaker Pipelines that enables data scientists to create automated end-to-end workflows for building, training, and deploying ML models. Data scientists can use Model Building Pipelines to define a series of steps for the ML workflow, including data preparation, model training, evaluation, and deployment.
• SageMaker SDK: The SageMaker SDK is a Python library that makes it easy to interact with SageMaker services, including Pipelines and Model Building Pipelines. Data scientists can use the SDK to create and manage pipelines programmatically, enabling integration with existing CI/CD pipelines.
• SageMaker JumpStart: SageMaker JumpStart provides a collection of pre-built ML models, algorithms, and workflows that can be easily integrated with CI/CD pipelines. Data scientists can use JumpStart to accelerate the process of building and deploying ML models, reducing the time and effort required.
4. Continuously monitor data and models in production to maintain quality
In the field of machine learning, it's essential to continuously monitor the data and models in production to ensure that they maintain quality and performance over time. Monitoring data and models can help identify and address issues such as data drift, model decay, and bias, ensuring that the model continues to perform well and generate accurate predictions.
Amazon SageMaker provides several tools and features to help data scientists and machine learning engineers continuously monitor data and models in production, including:
• SageMaker Model Monitor: A managed service that continuously monitors the data and predictions generated by your ML models in production. Model Monitor detects and alerts you to data drift, concept drift, and quality issues, enabling you to take corrective actions to ensure that the model continues to generate accurate predictions.
• SageMaker Debugger: Debugger also provides real-time metrics and visualizations of model performance, enabling you to identify and address issues quickly.
• SageMaker Autopilot: A feature of SageMaker that automates the process of building, training, and deploying ML models. Autopilot provides automatic monitoring and retraining of models, ensuring that they remain up-to-date and continue to perform well in production.
• SageMaker Clarify: A tool that helps identify and mitigate bias in your ML models. Clarify provides metrics and visualizations that enable you to understand the sources of bias in your models, and it provides recommendations for addressing those issues.
MLOps Tools and Technologies
MLflow
MLflow is an open-source platform for managing the end-to-end machine learning lifecycle. It was developed by Databricks, the company behind Apache Spark, and is now a part of the Linux Foundation's AI Foundation.
MLflow is designed to help data scientists and machine learning engineers manage their machine learning workflows, from data preparation to model deployment. It provides a centralized platform for tracking experiments, packaging code, and sharing models.
Here are some of the key features of MLflow:
• Experiment tracking: MLflow provides a tracking API and UI for logging and visualizing machine learning experiments. This enables data scientists to keep track of different versions of their models, compare results, and reproduce previous experiments.
• Packaging code: MLflow enables data scientists to package their code and dependencies into reproducible environments, making it easier to share and deploy models.
• Model registry: MLflow provides a centralized repository for storing and versioning machine learning models. This enables data scientists to share and collaborate on models, and to deploy them to production environments.
• Deployment: MLflow provides integrations with popular deployment tools such as Docker, Kubernetes, and Amazon SageMaker, making it easy to deploy models to production.

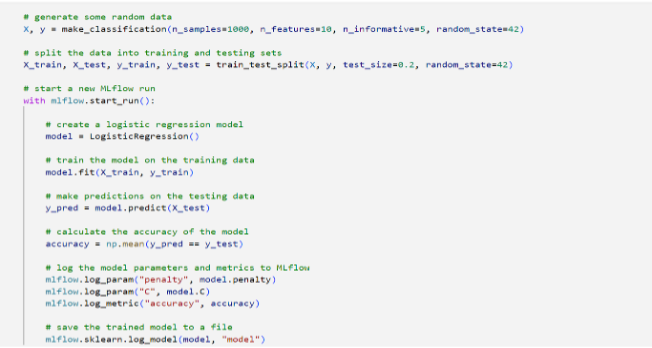
In the above example, MLflow is used to track the parameters and performance metrics of a logistic regression model trained on a synthetic dataset. The mlflow.start_run() function is used to create a new MLflow run, and the mlflow.log_param() and mlflow.log_metric() functions are used to log the model parameters and performance metrics to the MLflow tracking server. The mlflow.sklearn.log_model() function is used to save the trained model to a file and log it to the MLflow tracking server.
Amazon SageMaker
Amazon SageMaker MLOps is a set of tools and best practices to help developers and data scientists to build, train, deploy, and manage machine learning models at scale. It is built on top of Amazon SageMaker, which is a fully managed service that provides developers and data scientists with the ability to build, train, and deploy machine learning models.
SageMaker MLOps provides a suite of tools for automating and managing the machine learning development lifecycle. Some of the key features of SageMaker MLOps include:
• Model training: SageMaker MLOps provides a managed service for training machine learning models at scale. It can automatically scale training resources to meet the demands of large datasets and complex models.
• Model deployment: SageMaker MLOps provides a set of tools for deploying machine learning models to production. It supports a range of deployment options, including batch and real-time inference, and it provides automatic scaling and monitoring of deployed models.
• Model monitoring: SageMaker MLOps includes tools for monitoring the performance of deployed models in production. It can track key metrics such as accuracy and latency, and it can alert developers when performance issues arise.
• Model management: SageMaker MLOps provides a centralized repository for storing and versioning machine learning models. It can track changes to models over time, and it can provide a history of changes for auditing and compliance purposes.
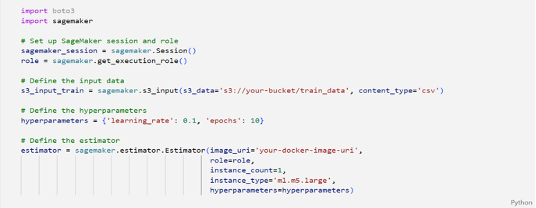

This code example demonstrates how you can use SageMaker to train, deploy, and manage machine learning models while incorporating MLOps practices such as data versioning, hyperparameter tuning, model versioning, and automatic model deployment. You can customize this example to suit your specific use case and data requirement.
Overall, SageMaker MLOps can help organizations to streamline the machine learning development process, reduce time to market, and improve the quality and reliability of deployed models.
Deployment Strategies[i]
Choose a deployment strategy MLOps deployment strategies include blue/green, canary, shadow, and A/B testing.
Blue/green
Blue/green deployments are very common in software development. In this mode, two systems are kept running during development: blue is the old environment (in this case, the model that is being replaced) and green is the newly released model that is going to production. Changes can easily be rolled back with minimum downtime, because the old system is kept alive.
Canary
Canary deployments are like blue/green deployments in that both keep two models running together. However, in canary deployments, the new model is rolled out to users incrementally, until all traffic eventually shifts over to the new model.
Shadow
You can use shadow deployments to safely bring a model to production. In this mode, the new model works alongside an older model or business process and performs inferences without influencing any decisions. This mode can be useful as a final check or higher fidelity experiment before you promote the model to production. Shadow mode is useful when you don't need any user inference feedback. You can assess the quality of predictions by performing error analysis and comparing the new model with the old model, and you can monitor the output distribution to verify that it is as expected.
A/B testing
When ML practitioners develop models in their environments, the metrics that they optimize for are often proxies to the business metrics that really matter. This makes it difficult to tell for certain if a new model will improve business outcomes, such as revenue and clickthrough rate, and reduce the number of user complaints.
Conclusion
In conclusion, MLOps is a critical methodology for organizations looking to scale their machine learning workloads. By combining best practices from DevOps with machine learning, MLOps enables organizations to automate and streamline the entire machine learning lifecycle, from development to deployment to continuous improvement.
— Author: Yasir Ul Hadi
Reference
[1] https://docs.aws.amazon.com/pdfs/prescriptive-guidance/latest/ml-operations-planning/ml- operations-planning.pdf
[1] https://aws.amazon.com/sagemaker/mlops/?sagemaker-data-wrangler-whats-new.sort-by=item.additionalFields.postDateTime&sagemaker-data-wrangler-whats-new.sort-order=desc
 Go to Swayam
Go to Swayam