
An enterprise engineering organization managing technical documents in varied formats across silos and fragmented systems partnered with Minfy to modernize how institutional knowledge is accessed and reused through a cloud-native Retrieval-Augmented Generation (RAG) platform. The solution enables conversational knowledge discovery and automated proposal generation, providing secure, scalable, and accurate access to historical information grounded in authoritative sources.
Business Challenge
The challenges were driven by business scale, operational efficiency, and the growing complexity of managing historical project knowledge.
Fragmented Knowledge Assets
Project documentation and data were distributed across on-premises file systems and legacy platforms in formats such as PDF, Word, and Excel, often following project-specific structures. While much of this data was structured or semi-structured, it was stored in isolated silos with inconsistent metadata and limited cross-project indexing. As a result, locating relevant precedent information across projects required manual navigation and reliance on individual familiarity, limiting systematic reuse of validated content.
Manual and Inconsistent Proposal Development
Proposal creation involved manually collating information from multiple prior projects, including scope descriptions, methodologies, schedules, and fee tables. Despite the presence of structured content within documents, the lack of unified access and automated synthesis made the process time-consuming and inconsistent across teams, increasing turnaround time and reducing standardization in proposal outputs.
Limited Cross-Project Insights and Benchmarking
Although historical project data contained well-defined parameters and structured sections, the absence of a centralized retrieval and aggregation mechanism made cross-project comparison and benchmarking difficult. Extracting insights such as trends, similarities, or reference baselines required manual effort, limiting the organization’s ability to leverage historical data for informed decision-making.
Solution Overview
A cloud-native Retrieval-Augmented Generation (RAG) solution was implemented on AWS to address both business and technical requirements. The platform consists of two tightly integrated functional components built on a shared ingestion, retrieval, and security foundation.
Component 1: Conversational Chat for Knowledge Discovery
The Chat component enables engineers and business analysts to query historical project documents using natural language.
Key use cases include:
- Discovering relevant technical precedents across historical reports and studies.
- Asking context-aware questions related to project scope, methodologies, assumptions, and engineering concepts.
- Identifying relevant documents and sections through natural language queries, reducing the need for manual file exploration.
Responses are generated by a large language model and are grounded in retrieved source documents, with inline citations allowing users to verify information directly against authoritative content.
Component 2: Automated Proposal Generation
The Proposal Generation component accelerates and standardizes proposal development by leveraging historical project data.
Key use cases include:
- Generating structured proposal drafts using predefined default sections, with the ability to add, modify, or remove sections based on user input.
- Updating or regenerating specific proposal sections while keeping all other sections unchanged within the same session.
- Incorporating relevant historical project context through RAG to ensure technical accuracy and alignment with established methodologies.
Shared Platform Capabilities
Both components rely on a common RAG foundation that provides:
- Automated document ingestion and enrichment.
- Semantic and metadata-driven retrieval.
- LLM-based generation with citation support.
- Secure, observable, and scalable API access.
Session and Conversational Memory Management
The system uses a session-based interaction model to manage context across both Chat and Proposal workflows. Each user interaction is associated with a unique session ID, under which all chat messages and proposal interactions persisted.
Conversational history for both Chat and Proposal modes is stored using LangChain’s DynamoDB-based memory, enabling continuity across multi-turn interactions within the same session. This allows users to iterate on discussions and proposal content while maintaining contextual awareness.
Context reuse between chat and proposal generation remains explicit and controlled, ensuring structured proposal outputs are not unintentionally influenced by exploratory conversations.
Architecture and Workflow
The solution is implemented as an event-driven, containerized architecture on AWS, designed for scalability, security, and operational efficiency.
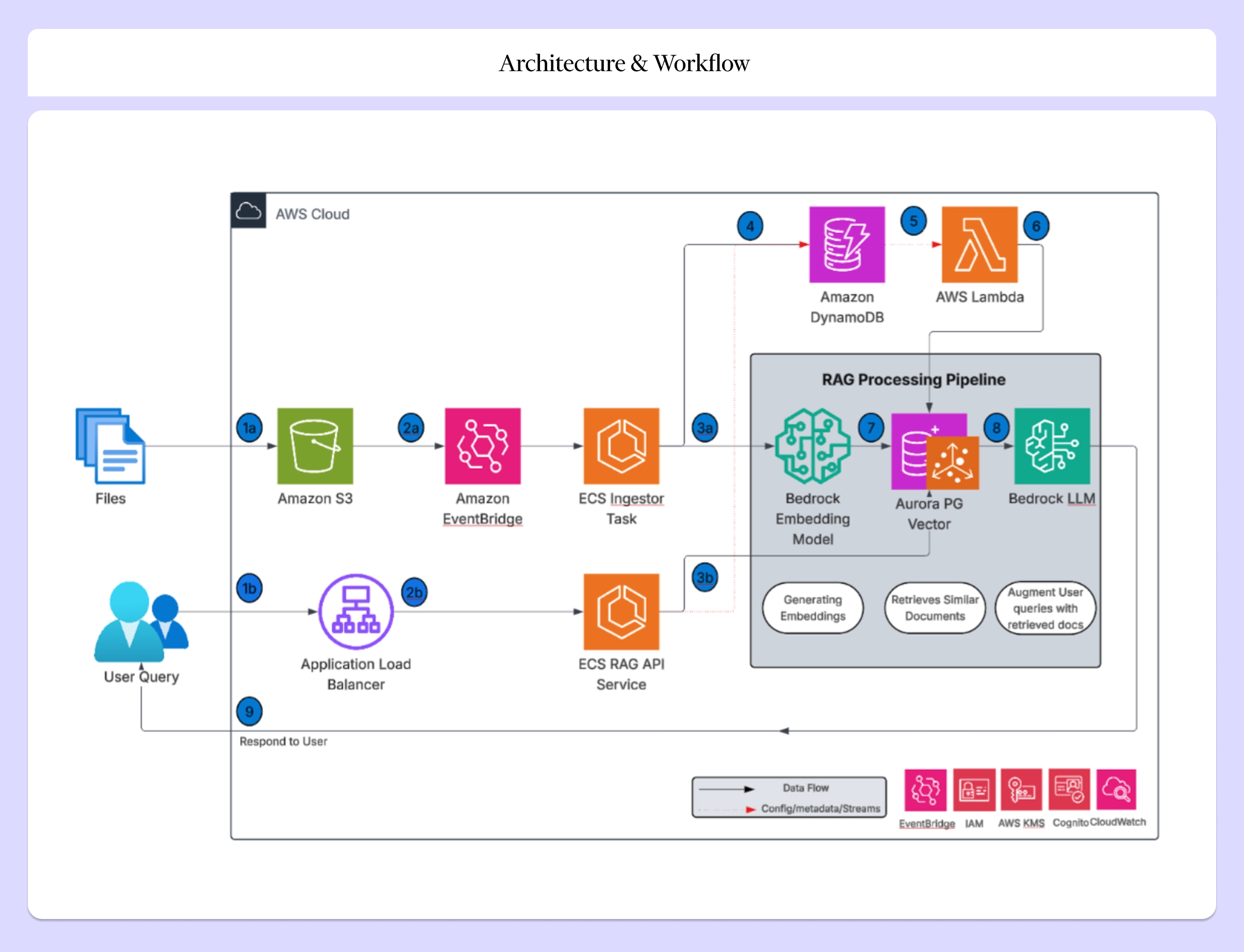
Core services include:
- Amazon S3 for document storage.
- Amazon EventBridge for orchestration.
- Amazon ECS on Fargate for containerized workloads.
- Amazon Bedrock for embeddings and LLM inference.
- Amazon Aurora PostgreSQL Serverless v2 with pgvector for semantic and parametric retrieval.
- Amazon DynamoDB for metadata, access control, and query logging.
- Application Load Balancer and CloudFront for secure access.
- AWS IAM, KMS, and VPC endpoints for security and governance.
End-to-End Workflow

RAG Pipeline Design and Implementation
Retrieval and Prompt Strategy
Prompt templates were designed to clearly separate system instructions, retrieved context, and user intent. Retrieval parameters such as chunk size, top-k selection, and metadata filters were tuned to balance relevance, latency, and cost.
Structured Data Extraction
The pipeline supports the extraction of structured information, such as fee tables and project attributes, from historical documents. Extracted data can be aggregated and compared using SQL queries, enabling benchmarking and analytics across projects.
Evaluation and Quality Control
A curated evaluation dataset was created to measure retrieval accuracy, response consistency, and performance. Results were used to iteratively refine chunking strategies, retrieval logic, and prompt templates.
Security, Authentication, and Governance
Security was embedded throughout the architecture.
- User authentication is enforced using Amazon Cognito.
- JWT-based authorization is validated on all protected API requests.
- HTTPS-only access is enforced end-to-end.
- Runtime IAM roles are scoped to least privilege.
- Administrative permissions can be removed post-deployment without impacting system operation.
This approach ensures compliance, auditability, and secure access to sensitive information.
Outcome and Impact
Business Impact
- 60% reduction in manual effort for proposal and report drafting by reusing grounded historical content.
- Significant reduction in search time for precedent documents, moving from manual file exploration to natural language queries.
- Faster turnaround for proposal preparation, improving responsiveness to business opportunities.
Data and Insight Enablement
- Reliable extraction and synthesis of structured data for benchmarking.
- Improved visibility into historical project parameters and trends.
- Foundation for future analytics and decision-support use cases.
Performance and Scalability
- Time to First Byte achieved within the 3–8 seconds for streamed responses.
- Architecture supports elastic scaling for concurrent users and growing document volumes.
- Serverless and containerized components optimize cost by scaling with demand.
- End-to-end observability enables monitoring of latency, errors, and usage patterns for continuous improvement.
Conclusion
Minfy’s implementation of an enterprise-grade RAG platform demonstrates how organizations can effectively unlock historical project documentation through AI-driven conversational knowledge discovery and automated proposal generation. By leveraging AWS-managed services, containerized compute, and strong governance controls, the solution delivers measurable business value while maintaining accuracy, reliability, and security. The architecture also provides a robust and extensible foundation for future growth, enabling organizations to scale data volumes, expand use cases, and derive deeper insights from their institutional knowledge.






