
Why DataTalk’s real advantage begins after the user asks the question.
Part 1 argued that the enterprise bottleneck is access.
Part 2 follows the machinery behind the answer.
That is where DataTalk becomes interesting. The interface may begin with plain English, but the product earns its value after that point: routing intent, choosing sources, composing queries, executing through governed connectors, joining results, masking sensitive fields, and presenting the answer in a form the user can act on.
A thin assistant can respond.
DataTalk has to be executed.

A Question Becomes a Work Order
Consider a question like:
“Show warehouses affected by severe supply chain risk events, their available quantities from ERP, and matching warehouse stock totals.”
That sentence is short. The execution path is not.
The system has to recognize that this is an analytical question. It has to identify which sources may contain supplier relationships, order data, risk events, and financial exposure. It has to decide which connectors to use, which fields to request, which filters to preserve, which policies apply, and how to assemble a final answer without leaking sensitive data into the wrong place.
That is the core technical challenge.
DataTalk treats the user’s sentence less like a message to be answered and more like a work order to be routed through a controlled pipeline.
MCP Changes the Integration Math
The more systems an enterprise has, the more dangerous one-off integrations become.
Without a common protocol, each AI workflow and each external system can become its own integration project. If there are M agent workflows and N data systems, the burden can drift toward M x N connection paths.
That does not scale.
DataTalk uses the Model Context Protocol (MCP) to change the shape of the problem. Workflows connect to a common tool interface. Data systems are exposed through MCP servers. The integration effort becomes closer to M + N: connect workflows to the protocol, connect sources to the protocol, and let the protocol carry the interaction contract.
That is the architectural value of MCP.
It gives DataTalk a standard way to reach databases, APIs, warehouses, lakehouse engines, and graph-oriented systems while keeping execution inside DataTalk’s governed pipeline. Vendor-provided MCP servers, community servers, and custom servers can all fit the same pattern. New sources do not need to force new access logic throughout the product.
This is not just cleaner engineering. It is what makes heterogeneous access operationally plausible.
The Query Composer Is Source-Aware
After intent routing, the Query Composer turns the user’s request into an executable plan.
This is where a lot of systems quietly fail. A model may understand the business question but still misses the actual schema, uses the wrong field, ignores source-specific syntax, or fails to account for API parameters.
DataTalk approaches query composition as a source-aware task.
It uses schema context, data-source hints, source capabilities, and configured documentation context. When documentation URLs are attached to enabled data sources, the Query Composer can use documentation lookup tools while preparing queries. That gives it a path to platform-specific syntax and examples rather than relying only on static model memory.
Recent work also tightened how schema guidance reaches the agent. Schema knowledge is injected into the task context where the Composer can actually use it during execution. That matters because retrieving useful schema information is not enough. It has to reach the agent at the right point in the workflow.
The technical goal is simple: the generated plan should reflect the real shape of the source, not an imagined version of it.
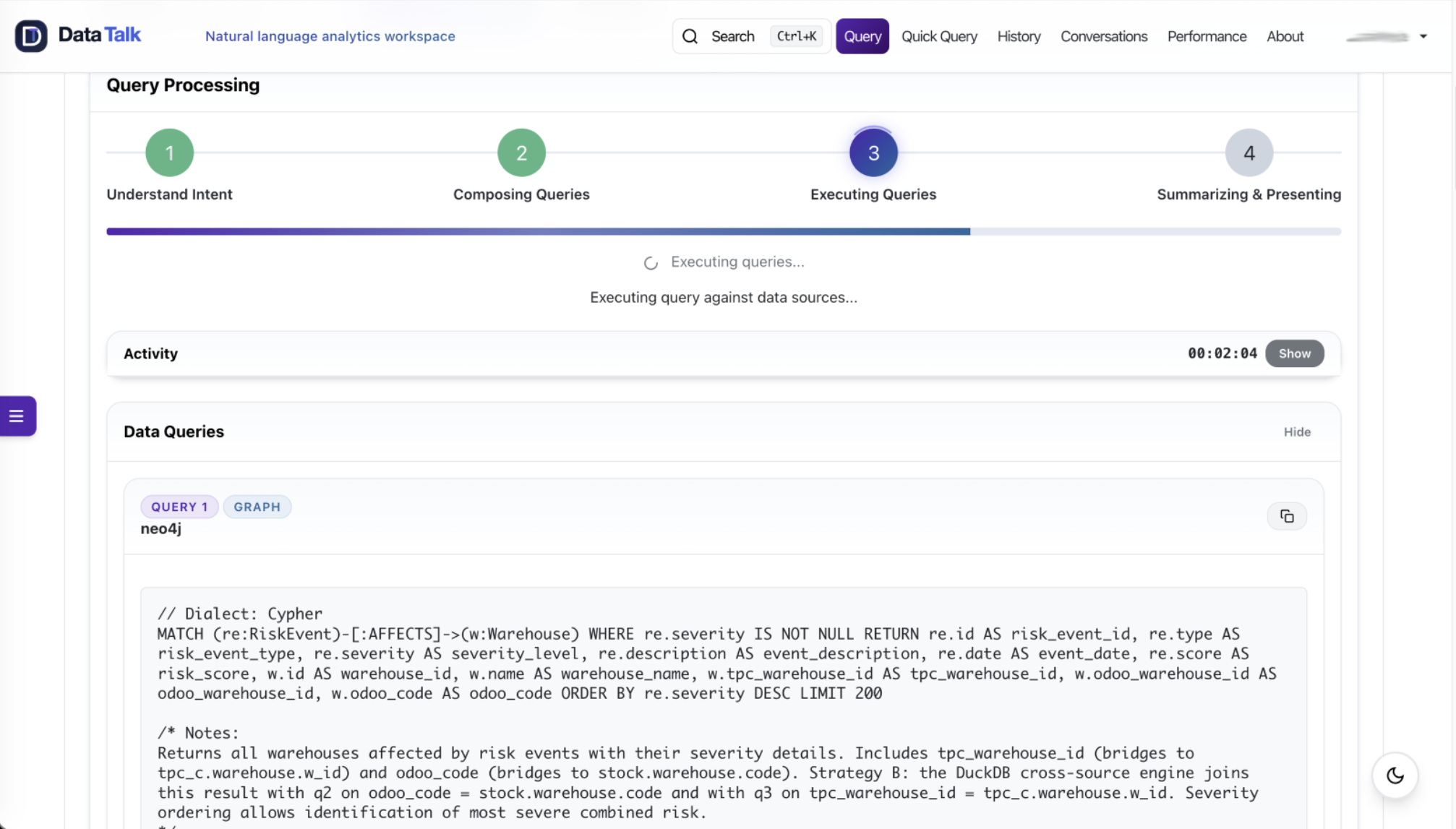
The Executor Defends Correctness
The Query Executor is where plans meet actual systems.
It runs queries through governed connectors, normalizes responses, detects failures, applies authorization and masking boundaries, and prepares outputs for downstream analysis and presentation.
This stage matters because real enterprise queries rarely fail in theatrical ways. They fail quietly.
A REST filter can disappear. A selected field can omit the column needed for a downstream filter. A date can mean different things across systems. A derived join key can be inferred incorrectly. A query can return zero rows because the join condition was wrong. An HTTP error can arrive as text and be mistaken for a successful response.
DataTalk has been hardened around those exact classes of failure.
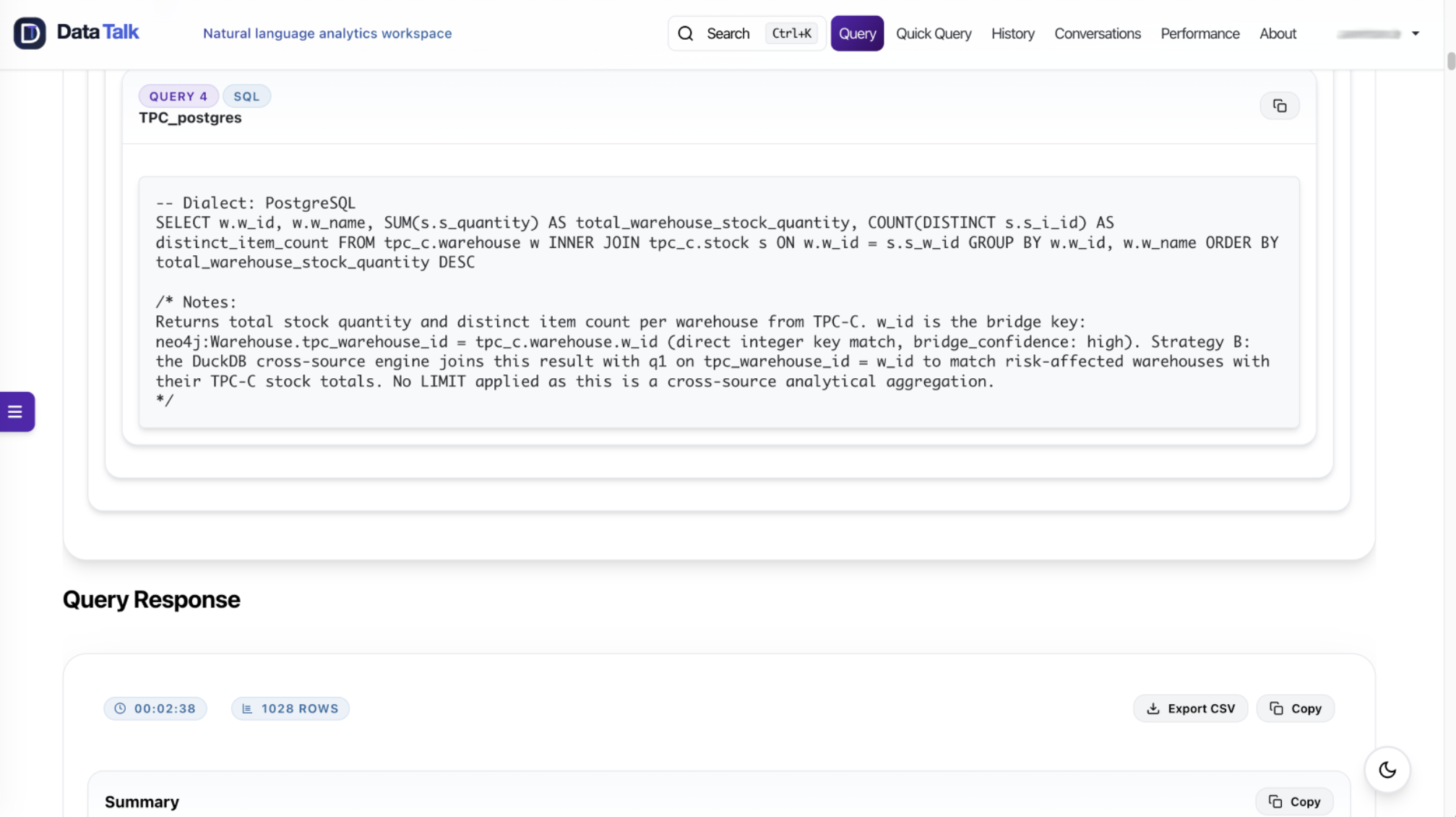
For cross-source joins, original query predicates are preserved into the join context. REST filter fields are retained when materializing data. The join engine has explicit guidance for aggregation, row-level comparison, enrichment, validation, and conditional categorization patterns. Field transformation hints can help with derived values. Date normalization handles time zone-aware comparisons. Post-join validation can catch suspicious zero-row or cartesian-like results and retry.
This is the difference between generating a plausible answer and defending the answer path.
Relationship Data Has Its Own Shape
Not every enterprise question is naturally tabular.
Supplier dependency, account hierarchy, fraud pattern, ownership chain, impact path, and customer influence questions often depend on relationships. Flattening those relationships too early can hide the structure that makes the answer meaningful.
DataTalk treats graph-shaped data as part of the enterprise data estate. Current graph-source work includes Neo4j-style deployments, but the important point is broader than one backend. Relationship data can identify the relevant entities, paths, and dependencies, while other systems contribute to operational, financial, or customer context.
This lets DataTalk answer questions that are awkward in pure SQL and incomplete when viewed through one system alone.
The product story should stay graph-aware rather than graph-vendor-specific. The value is the relationship model, not the logo on the graph database.
Governance Follows the Data
The more DataTalk can retrieve and combine, the more important it becomes to control what moves where.
DataTalk does not give LLMs direct access to enterprise data sources or credentials.
Source access stays inside governed execution layers. LLM providers do not receive connection strings, API keys, or autonomous access to databases.
That boundary is foundational.
Enterprise governance also has to decide who can ask what, against which systems, under which conditions. That is where RBAC and ABAC matter.
RBAC gives DataTalk a role-based control plane: a finance analyst, sales leader, auditor, administrator, and frontline operator do not need the same access. ABAC adds context to those decisions. Attributes such as user profile, group, source, query type, environment, clearance, and policy context can influence whether a request is allowed, restricted, filtered, or denied.
That combination is important because enterprise access is rarely a simple yes-or-no question. A user may be allowed to query revenue by region but not customer-level payment details. Another may see operational metrics but not personally identifiable information. A privileged role may access a source during normal business use, while a different context may require a stricter path.
DataTalk’s masking layer handles the next part of the problem: what happens after data is retrieved. Sensitive fields can appear in nested records, aliases, derived columns, graph responses, joined tables, cached results, feedback snapshots, and presentation inputs. Governance has to follow that movement.
That is why canonical masking and lineage matter. The salary field does not become harmless because it was renamed. A sensitive join key does not become safe because it appears in a derived result. A nested value does not become acceptable because it is wrapped inside a larger response envelope.
DataTalk’s masking model is built around that reality. It classifies fields, evaluates policy decisions, applies strategies such as redaction, partial masking, hashing, tokenization, nulling, bucketing, or type-preserving masking, and records audit context. If a masking or policy decision fails in a sensitive pathway, the safer behavior is to fail closed rather than expose raw data.
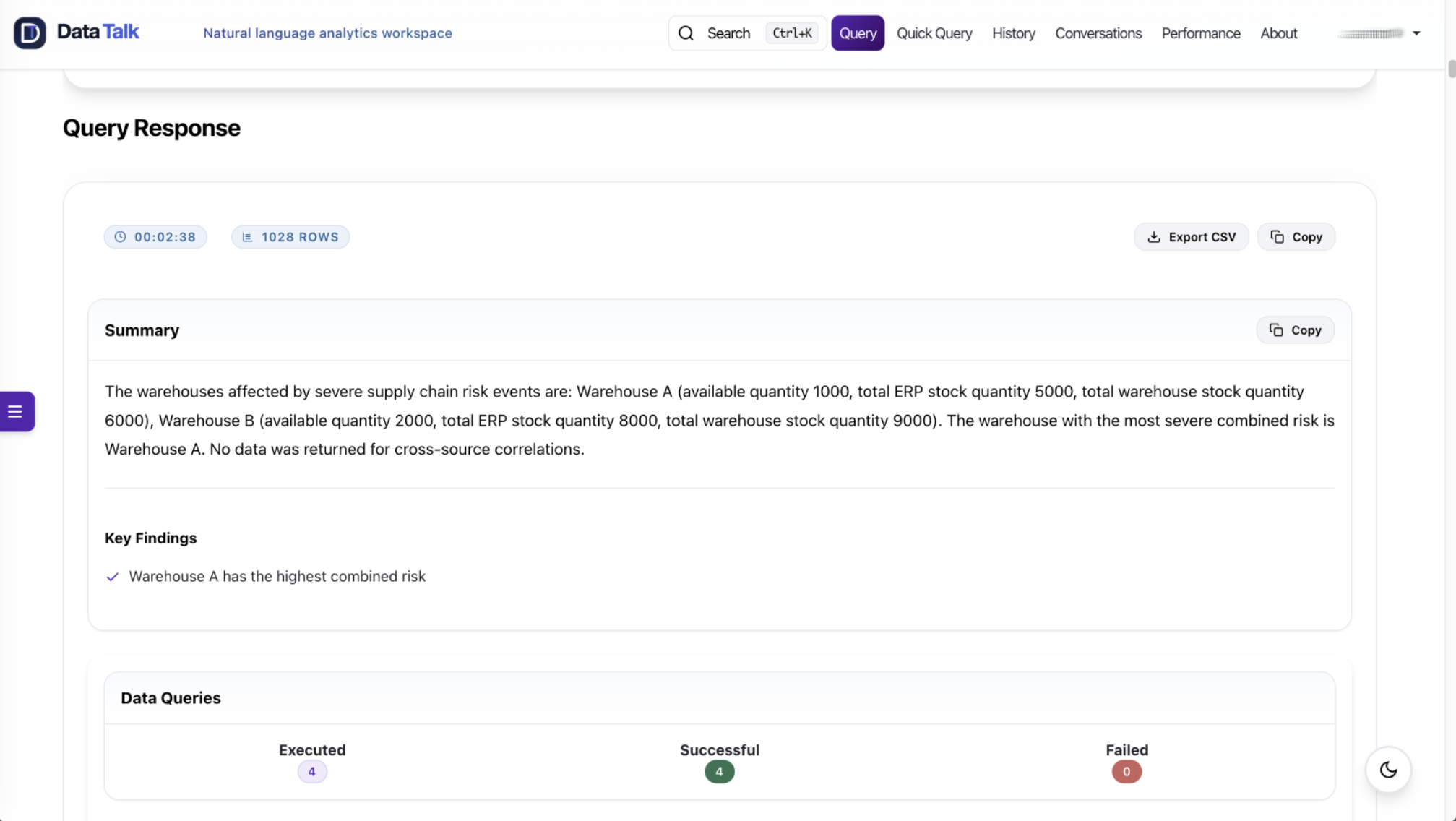
This is the enterprise version of “ask in natural language.” The user experience may be simple, but the answer path must preserve authorization, policy, lineage, and masking all the way through execution and presentation.
Stage 4 Is Presentation, Not Recalculation
The Results Presentation stage exists to make a governed result understandable.
It is not supposed to invent missing joins, formulas, rates, rankings, or business logic from raw rows. The analytical answer should be produced earlier in the pipeline. Stage 4 presents that answer for the user’s context.
That distinction matters for both accuracy and privacy.
By default, Stage 4 prompt context is built from sanitized aggregates, metadata, row counts, and policy-safe computed insights.
Raw result rows are not sent into cloud LLM prompts unless an explicit policy allows bounded, masked samples.
Visualization is also increasingly local and deterministic. Recommendation and specification generation can run inside the DataTalk process rather than depending on a cloud LLM. Similar data patterns should produce consistent chart choices: categorical comparisons should prefer bar charts, time trends should prefer line charts, and high-cardinality categories should avoid unreadable pie charts. Recent chart work also improves data labels and chart specification reliability.
The practical effect is that presentation becomes more predictable, more private, and more useful.
Reliability Lives in the Contracts
Some of the most important engineering work in DataTalk is invisible when everything goes well.
Agent outputs are validated, so malformed JSON does not silently break down the next stage. Tools return structured output directly rather than asking agents to reconstruct it. REST HTTP errors are detected as failures instead of being counted as successful data. Query-level token usage is persisted so teams can inspect consumption at the user-query level.
These details are not marketing features.
They are pipeline contracts.
And in an AI data product, contracts matter. Each stage has to hand the next stage something usable, validated, bounded, and inspectable. Otherwise, the system may still sound fluent while becoming operationally brittle.
The Technical Takeaway
The technical advantage of DataTalk is not that it can parse a sentence.
It is that the sentence enters a governed execution system.
MCP reduces integration sprawl. Query composition is grounded in the source context. Execution defends correctness across source boundaries. Graph-shaped data can participate in cross-source answers. Masking and lineage follow sensitive values. Stage 4 presents governed outputs without turning raw enterprise rows into prompt material by default. Reliability of work keeps the contracts between stages from becoming soft.
That is the substance behind the interface.
In the next part of this series, we will move from technical capability to enterprise adoption: what it takes for a system like this to be usable, governable, deployable, and supportable in production.







